Data Clustering Contest was a two-week data science and engineering competition held by Telegram in May. The Telegram team wanted participants to build a simple yet effective news aggregator that consolidates thousands of articles from various publishers and websites into a single page, which shows the latest news in real time, exactly like Google News, Bing News or Yandex News (with the Russian language inclining) do.
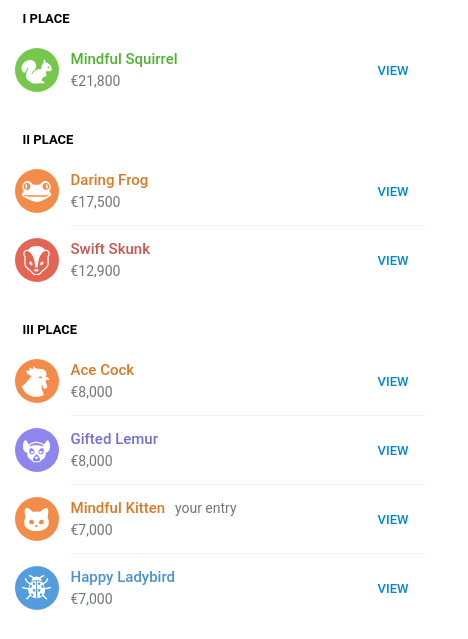
This was the second part of the competition whenever I totally missed the first part — and maybe for the better. I highly recommend reading the report from my Yandex ex-colleagues on how they placed 3rd place under the pseudonym Mindful Squirrel. Fortunately, now they made the worthy first place. I won the third place in this competition with the prize of 7000 Euros under the nickname Mindful Kitten (to be honest, it was quite nice that they named us, the contestants, this way 🙂 ).

My Initial Goal
I decided to try my skills given the fact I’ve been working on the search engine for quite some time. I want to be absolutely clear. I am not a Machine Learning engineer

when you are working in the search engines, you need to know at least how text/language ML works. Overall, you will not find many cool ideas right here about the ML itself but I tried to make the infrastructure around it fast. One of the main criterias for the contest was speed and I will show how I achieved the pretty fast results except server indexing (server response was one of the fastest among contestants) and why the latter was much slower.
Requirements
There were two parts of the contest — static and dynamic one. In the static one (almost the same as in the first stage of the contest) we needed to detect the language of the articles, separate news from non news, detect the categories and combine the similar news into threads and rank the articles in the threads.

In the dynamic one we needed to create a server which accepts the articles, detects their language, if it is news, detect the category, cluster news in threads and respond to the queries of the most relevant news for the given time, language and category.
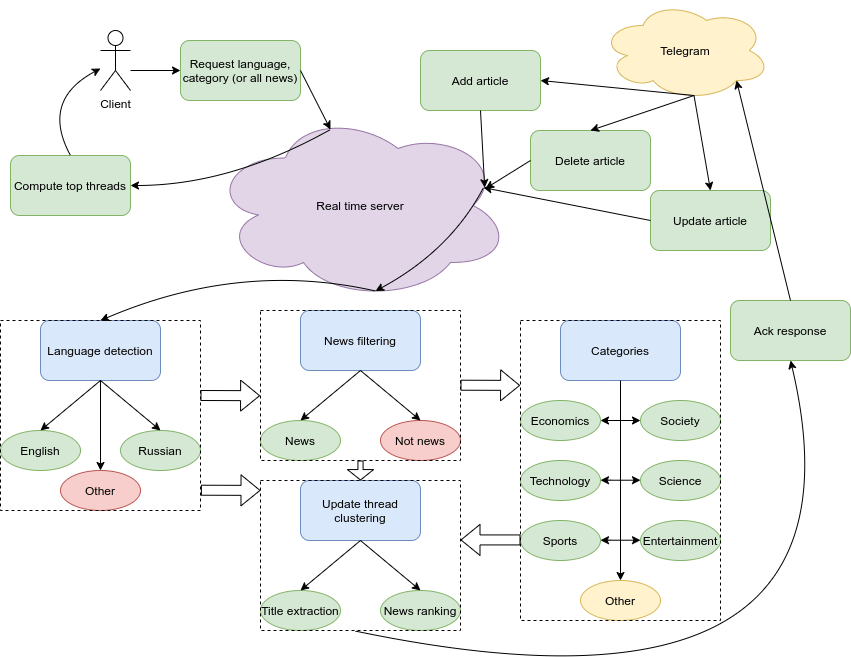
Server was tested on the x86_64 Debian machine with 8 CPUs, 16GB of RAM, HDD. The max requested time can be 30 days. The current server time is supposed to be the maximum article time (not news) in the index: it even means that the time can go backwards if we delete the most recent article from the index.
The final solution should be a binary without the connection to a network, has very few dependencies, no root (for example, this makes it harder to use some “fancy” databases like redis, etc).
Solution for a Static Version
Overall I was extensively relying on a fastText library. It is the library for learning word embeddings and training text classification models created by Facebook’s AI Research in 2016. The whole submission code was written in C++17 and some training was done through Python. But let’s start with something simpler. For example, thread management.
Thread Pool
As in the static version there are so many tasks that can be parallelized, I took a pretty decent implementation of the thread pool and patched it with my lock free queue (thanks to my university where we had to write it) which resulted in a slightly better performance rather than locking the mutex. (5.6k vs 5.9k tasks per second).
Parsing
All data consisted of HTML files from Telegram Instant View which parses most popular websites (around 5000+ of them) and provides a very lightweight HTML that is easy to read, load and parse.

There are several HTML parses in the open source community. Most popular one is libxml2. However, I found this was not an efficient one and it was around 3 times slower than Google’s Gumbo Parser. It is a parser which was tested against Google Search with over 2.5 billion pages which makes me confident that if there are some problems with the text extraction, they are definitely the Telegram’s problems. And in the end I found a couple of interesting surprises.
Like in many other HTMLs I filtered out <script>, <style>, <figure>, <iframe>, <address> tags to get the raw text which surprisingly turned out to be not enough. In the picture you can see what happened after that.

For some reason <iframe> tag was self-closing that resulted in such a mess. By HTML5 standard it is not a self-closing element and all browsers add a closing element to iframe. As I did not want to rewrite in that way because it would require one additional pass through the text, I decided (of course) to patch Gumbo library to meet the standards of the Telegram contest. Luckily, there are many self-closing tags and in the end it was a one line change
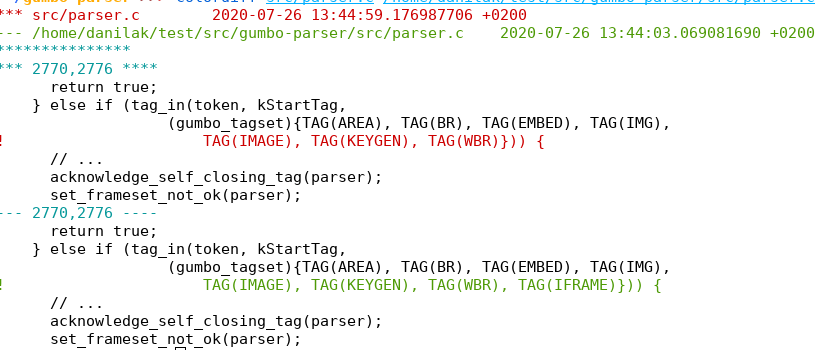
After that the text was correctly handled out.

Also, after some perf investigation, I found that around 15-20% of all the parsing was spent in function calls which were not inlined by the compiler. My final perf patch you can see here and I managed to come up with a 20% faster parsing algorithm: on average, each article was parsed in 0.4ms per thread which resulted in ~0.055ms per 8 threads or, alternatively, around 16-18k articles per second. I also believe I was lucky and HDD stored the articles in the directory consecutively where I managed to remove the latency of the HDD seeks (which are typically 8-12ms) or page cache made the job which is a more likely hypothesis.
During the parsing I also extracted the og:url, og:title, og:description and published_time attributes for the future use. It is not an interesting part though worth noting.
Language Detection
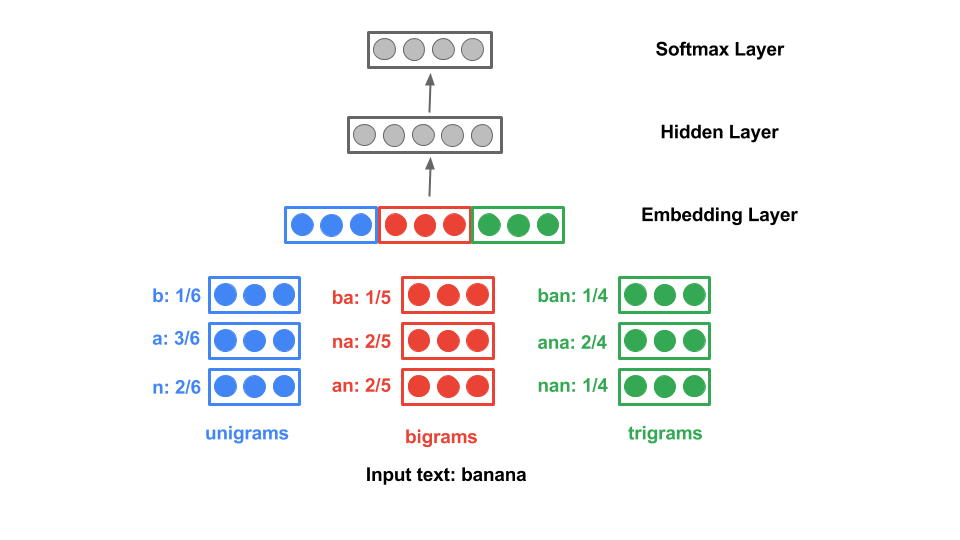
I was very interested how Chromium detects the languages of the pages offline and with respect to the fact it is written in C++, I was interested if I could do something similar. Finally I found CLD3 (Compact Language Detector 3) library which is a neural network model. It extracts the ngrams of the words or text and predicts with the 3 layers of the network which language is that.
I failed to find how accurate it was and went to read some papers about language detection and found out a nice paper Language Identification on Massive Datasets of Short Message using an Attention Mechanism CNN. The benchmarks and the accuracy of the models for short messages were provided and it helped me a lot with the decision

Unfortunately, the paper approach is hidden right now and I decided to look at CLD2 as it is 7.5 times faster than CLD3 and has even better accuracy. Though, I think the migration from CLD2 to CLD3 happened because of the accuracy for the web pages, though my testing of CLD2 against CLD3 showed 0.03% difference and almost all articles were highly debatable whether they are English or not because of the mess written inside.
CLD2 is a pretty abandoned repository with the latest commit 5 years ago and mostly is presented for historical reasons. CLD2 is a Naïve Bayesian classifier, using a combination of several different token algorithms. For most of the languages, sequences of four letters (quadgrams) are scored. For some big languages with lots of symbols the unigrams are taken. It is noted that “the design target is web pages of at least 200 characters (about two sentences); CLD2 is not designed to do well on very short text, lists of proper names, part numbers, etc”.
I decided to proceed with CLD2 in the end and a couple of surprises were on my way. I misread the initial statement and thought that detecting all languages was required. As it was 5 years old, some languages changed their ISO-639-1 code, for example iw -> he, jw -> jv, in -> id and mo -> ro. In order to stop language detection from failing, I was checking with the static table that language is inside the ISO-639-1 known languages. Unfortunately, there were articles with the languages that are not presented in ISO-639-1 and were only in ISO-639-2, for example, cebuano (which has a code ceb). In the end I gave up and was not printing them.
Also, I created a task in Yandex.Toloka to measure the precision and recall of my classifier. Toloka is a Russian crowdsourcing platform, just like Amazon Mechanical Turk. It turned out that they were more than 99.2% for English and Russian and I was pretty confident the results were ok. To fix several other issues I decided to do a cross validation only with the title and description of the article. Finally, the optimal algorithm for the problem was: if CLD2 is not sure (it can provide you the level of sureness) about the English language text, try out the title and description, otherwise use the first language. The metrics showed around 99.35% recall and precision for English and other articles were quite indecisive with some mess inside. That was a huge win. Performance of the library is extraordinary, it is around 0.2-0.4ms per thread per article.
In the end my language detection turned out to be the fastest across 3 days with less than 0.1ms per article. Yet, I don’t claim it is the best, other contestants might have better quality but no one knows how telegram evaluates the submissions.

News Filtering and Topic Classification
I decided to combine these two tasks into one and just added an additional label to the article as NotNews. The learning is almost exactly the same to what Mindful Squirrel did in the first stage yet I optimized the code and reestablished the models, i.e. was using the new learned ones.
I again utilized Yandex.Toloka and (a little bit) Amazon Turk to label a fraction of input data with the labels of categorization. I extended the dataset with publicly available data from the first contest, from the Ria.ru and Lenta.ru news dataset for the Russian language and the ones from BBC and HuffPost for English (thanks to Kaggle contests).
In the end I pushed around 50k articles to train for, cross validated with other submissions of the first round available on Github and got a pretty good model. Russian quality improved a lot but the English one did not have a super advance (especially in detecting other and not news labels). Overall my schema was looking something like that:
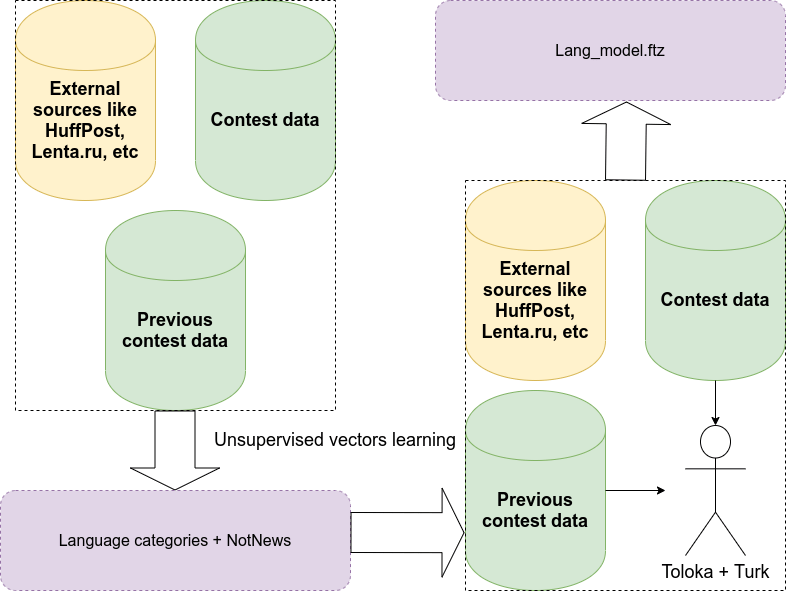
With the labeled data I trained the fastText classifier. Fortunately, engineers from Facebook made this library pretty fast with all SIMD accelerations so it looked pretty good for me. Unfortunately, I almost got caught to have a penalty in the contest because it is built with -march=native flag which includes all AVX-512 extensions on my machine. Likely they are not presented in the data-centers which Telegram is using so I decided to be more conservative and only used the extensions up to SSE4.2 and lost possibly at most 2-3% of the performance which is not bad.

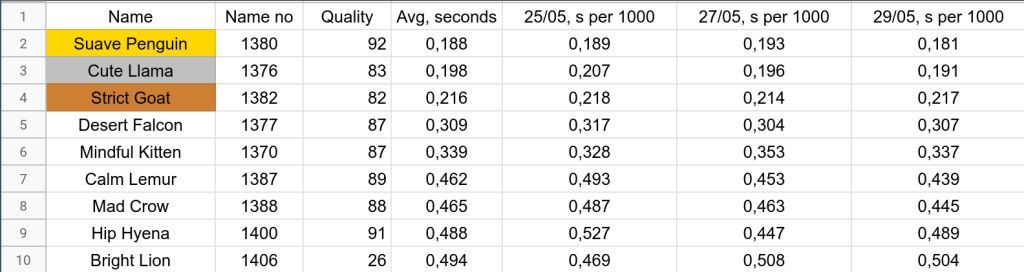
Unfortunately, I did not make the first place in terms of speed here but the submissions in top 3 did not have a (reasonably working) server so it gave me a pretty high chance to be one of the best for those who had servers.
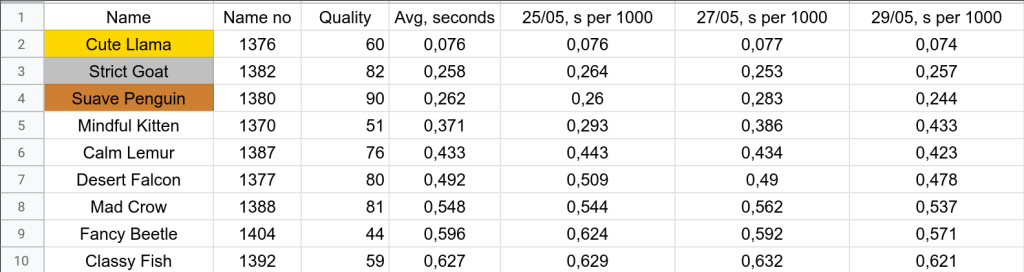
In categories detection it was better, second place speed in EN categories (with a pretty decent pre final result):

And a tie (but slightly better) in RU categories.

Also, worth noting, before applying the model, please, tokenize the text and remove all punctuation marks, etc. I lost several hours understanding what was wrong in some places.
Thread Clustering
In this part the contestants needed to combine similar news into the threads and rank the news inside them accordingly.
This is the part where I am going to talk about word embeddings. It is no secret that most of the text ML produces the embeddings and it is learned the way that if the distance between two embeddings is small, then the articles/news/pages are similar to each other. There are different types of “contextual” embeddings, one of the most popular ones are Word2Vec, DSSM, Sentence-BERT embeddings. I was not satisfied with the Word2Vec approach at all possibly because I failed to tune it properly. Fortunately, I felt pretty safe because I knew that average, min, max over word vectors of the fastText works pretty nice, in the end I retrained the model with the triplet loss function using a Siamese neural network from the Mindful Squirrel’s solution. Here I don’t understand the full magic behind the scenes, yet I only wanted to have at least some quality with the follow-up autotuning.
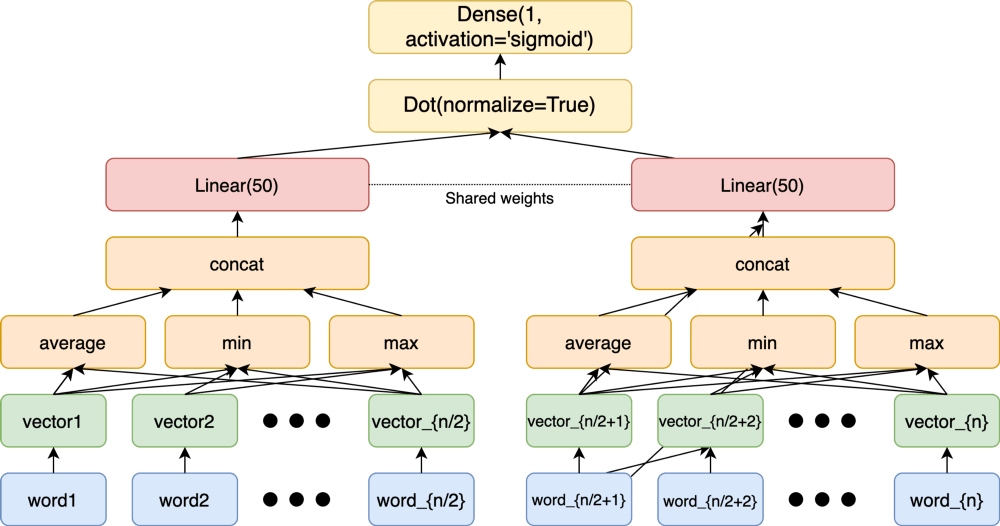
This model was pretty simple in the end and was using dot products which are highly optimized in the Eigen library.
In order to combine news in threads, I used SLINK algorithm: assume all nodes are 1-norm vectors and the edges between nodes are the L2 distances between them, then if we have a threshold 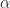
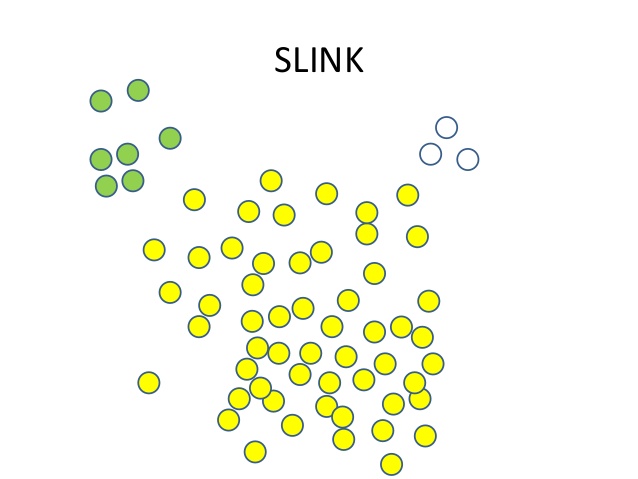
Unfortunately, it may lead to overpopulation in threading, for example, if the first node connected to the second one, and the second to the third one, it may happen that the first and the third are quite different. I firstly thought this not a big problem but in the end all COVID, accident news, earnings call reports had been combined together:

In the picture above news articles are connected by the topic COVID-19 but in the end it becomes a pretty huge cluster which is not easy to deal with. Though it is not accurate in some sense, I think this helped me to avoid many clusters with COVID news that are pretty irrelevant to each other and have 1 big thread talking about COVID overall.
Also, the time complexity was pretty huge for dealing with the hundreds of thousand of news and I decided to apply the algorithm with a time sliding window of 15000 docs and 3000 docs in the overlap. I assumed that if the news is not popular, it is very unlikely they are repeated after a long time.

Within the thread, the news articles are ranked by their PageRank weight and the time between the most recent article in the thread. Actually, there are pretty few really good news agencies so it was even a matter of human intervention to boost some very authoritative newspapers. Also, one of the weights was the mean similarity with other news which was pretty easy to recompute in real time but we will talk a bit later about it.
In the end, threads clustering turned out to be one of the fastest among contestants

Dynamic Part
As you may already forget, we also needed to write a server that indexes the news and responses with the best threads within the given range. Just a reminder what we should do
It means we need to index all upcoming news in real time. The rules of the Telegram contest were vague in terms of what consistency we should provide, for example it was absolutely not clear if we can produce news after some time, meaning if we can update the top news once in a while like all aggregators do. Unfortunately, some of the solutions were tested against this “common sense”, the top news requests were coming right after the requests when all news were indexed.
Indexing
First thing to note, that updating the article is basically a deletion+insertion request, so this was a pretty easy reduction. Unfortunately, that also increased the complexity — I could not easily parallelize the requests by category or even by language because with the article update, it may change even the language — and I needed to provide strong consistency which resulted in me using a global lock. I could not split the request into two because in the middle there can be another request modifying the article and the result can be skewed or not expected. The modifying and deletion requests were tested by Telegram but from the logs I obtained not a single article changed its language, possibly it was just done if the article was updated.
Current time of the server is the maximum time of the article (not news) so I needed to store metadata for all articles. It also means that the time can go backwards with the articles deletion so it also increased the complexity that I cannot easily update the current time in one atomic operation. Was this tested by Telegram? I doubt.
Indexing news consisted of one more parameter — TTL (Time To Live), it was stated that if TTL + article published time passed the current time, the article should be deleted. With the consequence that the time can go backwards, I needed to store all articles either way.
How to Store?
First I thought of using something external like ExtremeDB and/or SQLite3 but their locking and parallelisation mechanisms turned out to be really slow for my needs. Also, their C++ APIs are not flexible to use and require some time for careful investigation.
To store documents I used protobufs as I love this format a lot for its simplicity and I worked in the companies where protobuf is heavily used. I honestly believe this format is hundreds times better than JSON and is one of the best statically typed formats to use.

Also, one more requirement to the contestants was that if the server restarts, it should load the index and respond like usual. That’s why it was important for me to store embeddings rather than text: to combine news into threads I only needed them. Also Telegram did not require store text of the article in any form so I saved lots of CPU and disk resources. Upon the restart, I used the static schema solution already knowing the category and embeds of the news.
Actually I thought I could proceed with something really simple. I did not store all in one file, all docs were sharded. When the doc comes and I need to store it, I choose 2 random shards to store and pick the one who has the lowest number of docs, store it. If I needed to extract the document, I just needed to do two lookups. Why have I chosen two random shards? That’s because in one random shard strategy the maximum number of the docs in one shard (given that the number of articles is 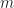


As a hash key I used the names of the files. As the number of shards was 10000, I found that reasonable for a monthly number of articles (up to 10mln).
Thread Updates
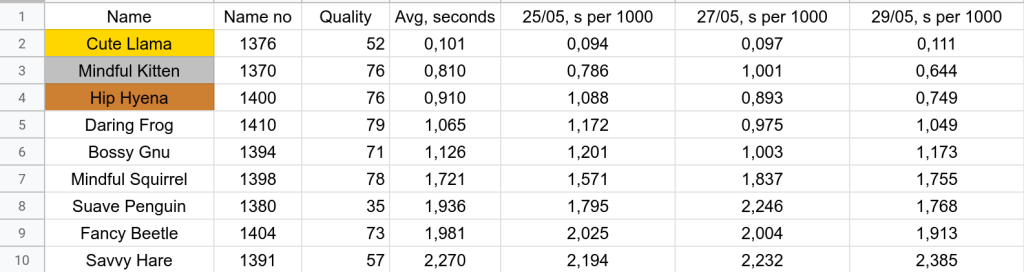
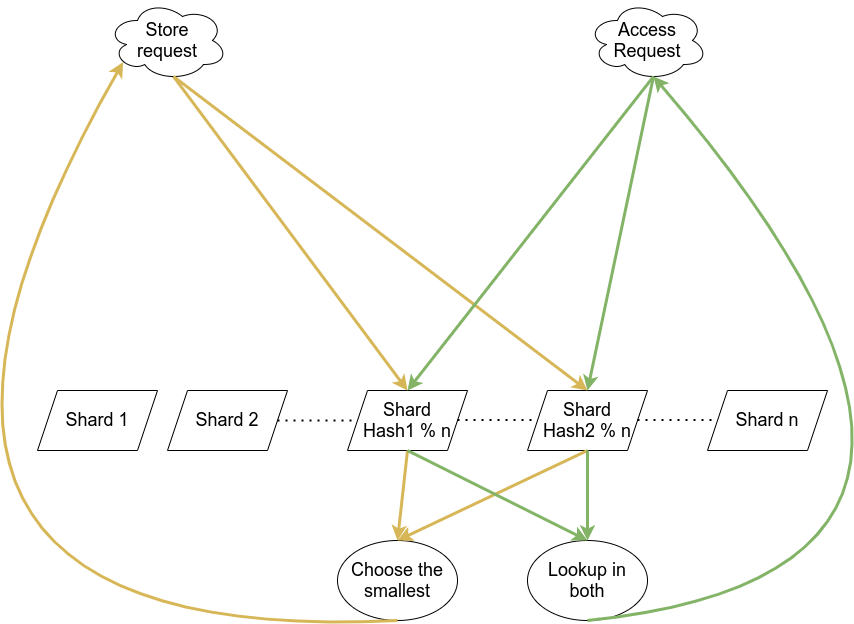
I highly prioritized the read responses as in the news it is ok to wait for 5-10 minutes to propagate the indexing requests but it is very user facing to respond as fast as possible. As you can see, I was top two in response times. Mad Crow, unfortunately, had hardly any working server overall and I believe I got additional points because of that decision.
I decided to store globally for all time all the threads that I have. Partially because I was paranoid of the fact that the time can go backwards, because of strong consistency, etc.
To find a thread for the article I decided to use k-NN approaches (k nearest neighbors) and especially HNSW (Hierarchical Navigable Small World) similarity embedding search algorithm. According to ANN benchmarks it is one of the fastest algorithms. Yet, right after the contest Google published its own version of nearest neighbor search called scANN which in my opinion has the advantage that it utilizes the SIMD instructions better with its design and overall it is really faster, maybe for 20-30%. HNSW was more than enough for me, also I quite nicely understand how it works. Actually…
How does HNSW work?
A naive solution to the k-NN problem is to compute the distances from a given query point to every data point within an index and then select the data points with the smallest k distances. It does not scale to the sizes of hundreds of thousands of vectors. An approximate k-NN algorithm may greatly reduce search latency at the cost of precision.
The HNSW algorithm focuses on reducing the number of comparisons by building a graph data structure on the constituent points of the data set.
With a graph data structure on the data set, approximate nearest neighbors can be found using graph traversal methods. Given a query point, we find its nearest neighbors by starting at a random point in the graph and computing its distance to the query point. From this entry point, we explore the graph, computing the distance to the query of each newly visited data point until the traversal can find no closer data points. To compute fewer distances while still retaining high accuracy, the HNSW algorithm builds on top of previous work on Navigable Small World (NSW) graphs. The NSW algorithm builds a graph with two key properties. The “small world” property is such that the number of edges in the shortest path between any pair of points grows poly-logarithmically with the number of points in the graph. The “navigable” property asserts that the greedy algorithm is likely to stay on this shortest path. Combining these two properties results in a graph structure so the greedy algorithm is likely to find the nearest data point to a query in logarithmic time.

HNSW extends the NSW algorithm by building multiple layers of interconnected NSW-like graphs. The top layer is a coarse graph built on a small subset of the data points in the index. Each lower layer incorporates more points in its graph until reaching the bottom layer, which consists of an NSW-like graph on every data point. To find the approximate nearest neighbors to a query, the search process finds the nearest neighbors in the graph at the top layer and uses these points as the entry points to the subsequent layer. This strategy results in a nearest neighbors search algorithm which runs logarithmically with respect to the number of data points in the index.
For full graphs it is working really nice and easily provides the insertion queries. Yet, deletion is a bit more complex because you need to somehow deal with the NSW layers and it might take some time to reconstruct them.
Thread Ranking/Updates
I utilized the online-hnsw library in order to support insertions, deletions and k-NN queries. But in a bit of an interesting way.
As you remember, SLINK clustering is transitive, it just puts two vertices in one cluster if there is a path between them where all edges are of weight 

I find k nearest neighbors and when I stop finding by the same threshold as in the static version, I combine all threads in one. It guarantees that eventually we will have the cluster as in the SLINK algorithm (if k-NN search is accurate, of course). Approximately it works almost perfectly and within a small time all relevant articles are combined together.
When combining, I need to do several things, for example, to update the similarity matrix which is basically done incrementally:

This recalculation method is working very nicely when we merge big clusters with very small ones. Unfortunately, I made a very silly bug there, and in the submission and full matrix was recalculated which resulted in this after 9 days of server uptime.

That basically means that huge clusters (like COVID) were constantly updated and matrix multiplication was taking too long to update the similarity values. I also put the restriction on the cluster size but because of another bug it worked only when one document is merged with the big cluster.
Threads ranking is basically the sum of the pagerank weights of the articles inside plus small constant for all other news agencies. Small threads up to 5 docs are linearly penalized which works very good for small ranges of time (for example, show the news for the past 1 hour). News in clusters are sorted by sigmoid of the most recent time plus mean of the similarity matrix.
Thread Responses
We needed to show the most relevant news depending on the given time range since the latest article (in the tests there were 1 hour, 3 hours and 1 day, in the statement it could be up to 30 days). Also, people can request categorized news like Science news for the last 1 hour in Russian language.
As I was updating the threads in real time, I just was looking up through top 
Unfortunately, when the time range is very small, it could happen that there is no very new news in the top
So, the news responses were very fast because the threads are updated in real time and the threads are precomputed for the response. Also, I was not including more than 100 threads in the response because starting somewhere from the 50-60th threads, all threads contain only one article so that it does not make sense to show. Also, it helped to improve the performance a lot without any loss in the quality (cmon, no one looks at more than 10-20 news at once).
How I tested
The solutions were tested on pure Debian, I rented for 3-4 days the Digital Ocean Debian machine in order to better understand the performance of my application.
I wrote a bunch of tests for the static part, unfortunately, the dynamic part was written once and tested with my eyes. Build system was CMake and it was fairly easy to statically include all the projects I needed — gumbo, online-hnsw, abseil, http server, thread pool, protobuf, boost. Of course, I used all kinds of sanitizers to catch any issues which is basically a mandate in the modern C++ world.
Unfortunately, I was not able to benefit the server from multithreading because I could not do it for languages as the article may change its language and the judges may test the skew issues. So on each mutating request I acquired WriteLock, on each response request ReadLock with the higher priority not to block the clients.
Conclusion
Whole application was written in C++17 when learning algorithms were in Python, I spent around 5-6 days on the static part and then 8-9 days on the server part 4 of which I was debugging all the cases that I am correctly updating the pointers to threads, thread combining, etc. Of course, I made a couple of bugs that I described above.
What I liked
Finally some engineering contest and not sports-programming or pure ML competition on Kaggle. I liked that we were given some data to test on. I enjoyed writing C++ code and CMake was very easy to set up (I admit that maybe it is already easy for me as I spent enormous time in the past doing that kind of job). The problem was good and novel enough to work on from scratch.
Prize pool also was quite nice, I was immediately communicated to receive my prize.
What I did not like
Absolutely no transparency on how we can communicate with the judges about the questions that arise. For example, nothing was said about which type of disk would be used or if we could delay the index updates (turned out to be that no or not always).
No transparency in how the evaluation or testing process happens. Likely they hired many volunteers to outsource the categorization and thread quality. Yet, we did not know how with which instructions and why they are silent about this. Incremental process of evaluation would be very fun to watch, for example.
It was unclear if we can work together or not. I did not work with anybody but I would definitely want to have an ML partner to flesh out and look for bugs. Some other teams were of 4 and more people which is a bit unfair(?).
Also it would be nice to have at least some statistics from Telegram on the data, at least the view count that they have in Instant View. With the raw data it was much harder to get what is relevant and farm the data for the training stages.
Unfortunately, I cannot open source the solution for now because I need to get an approval from my employer but as soon as I get it, I will probably open source that crunchy code 🙂 .
The second place in the contest can be placed without the server side which is quite strange, even in the final message the judges said: “Clustering tasks similar to the previous round (sorting by language, news or not, categories and threads) carried a lower weight. Overall speed of the algorithms influenced the final score.”
True Conclusion
I managed to combine lots of ideas into one place and compete with many other contestants from ML sphere quite a little. I am satisfied with my results and looking forward to participating in other contests from Telegram. Of course, I am not satisfied with the code quality and what I haven’t managed to try or flesh out.
Also, this type of work gave me a good personal understanding that I show myself best when I have competition and/or tighten up by the deadlines. In the end, I show at least something acceptable.
My Telegram channel (in Russian)
