Hello everyone, today we are going to talk about C++ performance. Again, another “usual” perf blog as you may think. I promise to give really practical advice and don’t get bullshitty (okay, a little bit) talks about how C++ is performant. We are gonna roast the compilers and think about what we should do about it (or should we?). Let’s do a bit of fact-checking:
Fact #1. Compilers are smarter than the programmers
Resolution: it’s exaggerated
Of course, we do have really awesome compiler infrastructure as GNU or LLVM, they are doing a massively great job in optimizing programs. Hundreds of PhDs were wasted done on researching that and what the community achieved is flabbergastingly.
However, the problem of finding the optimal program is undecidable, and nothing we can do about it. Even small cases of invariant loads are not simplified, after looking at the examples below it seems that compilers cannot do anything useful:
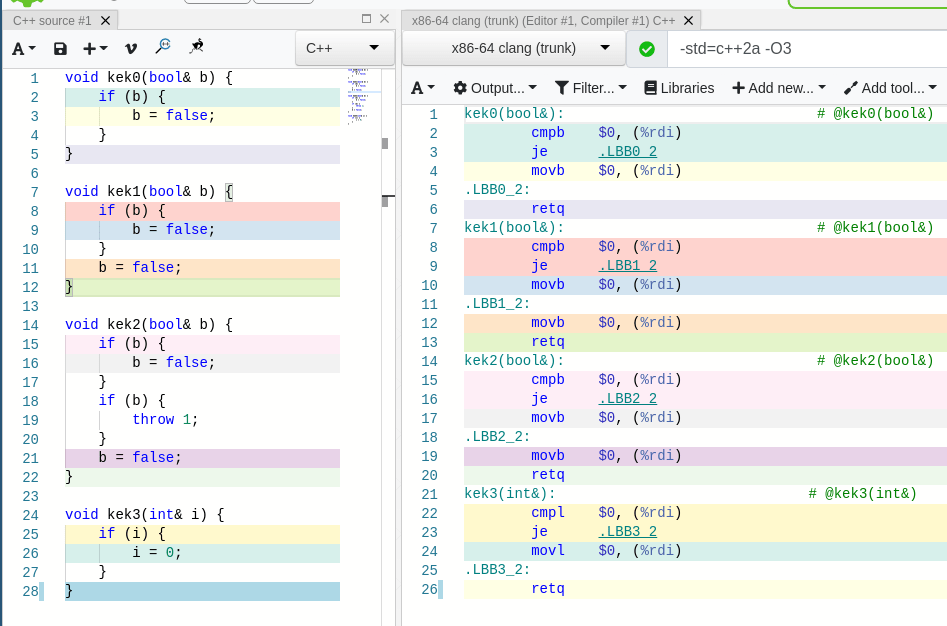
None of the expressions were optimized to one load but they clearly should be. I was always thinking that compilers should find all possible invariants in the code and simplify the constructions to minimize the execution cost.
Compilers cannot understand the complex properties of the ranges being sorted or increasing which can help understanding more structures. Actually, that’s because of the compilation times — understanding the sorted property is rarely used and is not so easy to check or make the programmers annotate.
Also, of course, no compiler will optimize your quadratic sort into a O(n log n) sort because it is too much for them to understand what you really want and other factors can play a role — for example, the stability of sorting which affects the order of equal elements, etc.
Fact #2. C/C++ produces really fast code
Resolution: false
I don’t agree that C/C++ itself provides the best performance in the world, the only thing I am convinced in: C/C++ provides you the control over your performance. When you really really want to find the last nanoseconds in your program, C++ is a great tool to achieve this, for example, you can look at my blog entry on how I managed to put 16 byte atomics in the Abseil, doing it in other languages require much more time and not that expressive.
Fact #3. inline keyword is useless when concerning C/C++ performance
Resolution: partly but false
I heard that so many times that inline keyword is useless when it comes to C/C++ performance. Actually, it has a bit of history, inline really does not mean that function should be “inlined” in the code, it is not even a hint, it is a keyword that solves the following problem: assume you have two cpp files with the include of any entity that might have a one definition rule conflict: it might be a function or even variable, then you will get a compiler error, inline keyword promises that it is ok to duplicate the function in different translation units and have the same address.
The usual understanding of the performance of inline functions comes from the C standard
A function declared with an
Page 112 of ISO/IEC 9899:TC2inlinefunction specifier is an inline function … Making a function an inline function suggests that calls to the function be as fast as possible.(118) The extent to which such suggestions are effective is implementation-defined.(119)
So, let’s once for and forever for the most used cases get:
- constexpr functions are implicitly “inline”d
- general template functions are implicitly “inline”d
- function definitions in classes are implicitly “inline”d
- static constexpr variables in classes are “inline”d from C++17
Don’t put inline specifiers for these entities and force your developers to remove them within the code review, educate them, put in styleguides, etc.
Ok, inline is good but did you know that inline functions have a better threshold for inlining? For example, in clang, functions marked as inline have a better threshold in actual code inlining than usual functions, for example, see this:

So, inline keyword might help only in free functions within one translation unit, otherwise you either need to mark the function inline or it will be implicitly that way. And yes, it does help the compilers to optimize your programs. Yet, if you are having an interview and somebody asks about the inline keyword, tell about the performance because most of the interviewers expect this and as we all know, interviews are not about the actual knowledge, they are about understanding what people want to hear and find out about you. I actually once told the whole lecture about inline keyword to the interviewer and they were kind of impressed but all they wanted to hear is that it helps the performance. Unfortunately, the truth is more complex and boring.
Though the inlining in the compilers makes a big deal in optimizations and code size and we will look at this a bit later.
Fact #4. -march=native gives a good stable performance boost
Resolution: yeah, probably true but …
These flags allow you to tell the compilers what kind of hardware you have and optimize the program specifically for this type of hardware.
But it is not portable, once you compile with that flag you must verify it does not do any harm to the hardware you are running your code with. Or you compiled the code on the right hardware.
I personally don’t recommend using this flag anywhere as it will 100% break things and in my experience, it does not provide lots of benefits for already well-tuned programs. Most of the programs are SSE optimized and using AVX-AVX-512 can cause real troubles within the transition as explained in this paper. Well, if you are sure, use AVX everywhere and make sure non of the SSE code follows your critical path or the benefits from AVX are significant.
Enough talking, give me perf
In recent times I really found myself repeating to many different projects the same thing and they all helped to gain around 5-15% performance boost just in a few lines of toolchain settings but first, a little bit of overview
GCC vs Clang
I personally don’t believe in a fast moving future for GCC toolchain and for now this compiler wins mostly for supporting a huge variety of platforms. Yet, the overwhelming majority of all machines are now one of x86, ARM, Power, RISC-V and both compilers support these architectures. Clang is giving more and more competition, for example, Linux kernel can be built with clang and is used in some 6 letter companies and Android phones. Clang is battle-tested continuously from head within at least 3 companies out of FAANG which contain around a billion (rough estimation) of C/C++ code overall.
I do want to admit that GCC became much better than it was several years ago with better diagnostics, tooling, etc. Yet, even later news for GCC such as a huge bug in memcmp optimizations which, for example, already can contain at least 10 bugs in your default OS software. As I understand correctly, the bug was fixed after 3-5 weeks of identifying which is already an enormous amount of time for such a bug to be alive. People suggest using the option -fno-builtin but this will definitely lead to huge performance regressions, for example, all memcpy small loads are going to be replaced by a call and even the code in the fastest decompression algorithm LZ4 will become less efficient: in the upper code memcpy is replaced by a 16 byte vectorized load, in the bottom picture this is an entire jump to memcpy which can be a huge penalty

For example, in my experiments even -fno-builtin-memcpy can cause up to 10% performance penalty, for example in ClickHouse benchmark.

-fno-builtin-memcpyThe situation with memcmp is pretty much the same but if you definitely need to mitigate the bug — update the compiler, use Clang or at the very least use -fno-builtin-memcmp.
Overall it means that GCC was once extremely unlucky with the bug and no prerelease software caught it. There are likely several reasons for that: hard to test continuously GCC from head, hard to build the compiler overall (against LLVM where you just write 1 command to build the whole toolchain).
GCC vs Clang tooling
I feel that Clang is an absolute winner here. Sanitizers are much more convenient to use in the ecosystem, static analysis tools together with the API which help the code to evolve and recover from mistakes.
GCC vs Clang perf
Still, there are debates about what is faster between these two compilers. Phoronix benchmarks are the good estimations of what is happening on a broad range of software. Want to admit that compile times for Clang are significantly faster than GCC ones, especially on C++ code. In my practice I see around 10-15% faster compile times which can be used for cross-module optimizations such as ThinLTO (incremental and scalable link time optimizations).
Yet, with clang-11 and a little bit of my help we finally managed to achieve the parity between gcc and clang in performance at ClickHouse:

Most of the performance came from just updating the compiler, however the last 0.5% we got from ThinLTO and the compile time was still faster than GCC without any cross-module optimization

So, after that I decided to go a bit further, and with a couple of lines of toolchain code to experiment with the main ClickHouse binary, I managed to get an extra 4% performance. Let’s talk about how to achieve this.
Clang perf options I recommend
-O3by default, obviously-flto=thin. This is a scalable cross module optimization ThinLTO. As a bonus we also got the binary size reduction from 1920mb to 1780mb and after that GCC was not faster than Clang. In my practice, this should give from 1% to 5% of performance and it always decreases the binary size and consumes less memory during the compilation than LTO which can easily OOM and painfully slow. By the way, here is a good presentation on ThinLTO and the memory consumption vs full link time optimization is the following

And compile times

As it is scalable, you can easily put it in your CI or even build once in a while for release to check that it is fine. In my practice, ThinLTO provides almost the same performance optimization and is much more stable. For ClickHouse it gave 0.5% performance gain and smaller binary.
-fexperimental-new-pass-manager. LLVM IR optimizations consist of passes that transform code trying to reduce the overall execution cost. The old pass manager was just containing a list of passes and running them in a hardcoded order, the new pass manager does a bit more complex things such as pass caching, analysis passes to determine better inlining and order. More info you can find in this video and in these two pdfs (one, two). The development of new pass manager finished in 2017 and Chandler Carruth sent the RFC at that time, since then it has been used at Google permanently and polished by the compiler developers. In August 2019 it was once again to be said to be by default and as of October 2020 it is still not by default but the bitflip diff is ready. In my practice that gives 5-10% compile time reduction and 0-1% performance. In ClickHouse together with ThinLTO it produced 1% performance in total, 7% compile time reduction and 3% binary size reduction from 1780mb to 1737mb. I highly recommend using this option and to test it now — you can possibly catch the latest bugs and it will be by default anyway in the near future (I really hope so).-mllvm -inline-threshold=1000. This option controls the actual inlining threshold. In clang by default, this number is 225. Inlining turns out to be really important even for middle size functions. In my experience this really performs well for numbers around 500-2000 and 1000 is somewhat a sweet spot. This, of course, will increase the binary size and compile times by a fair amount of percent (10-30%), yet it is a universal option to find the performance here and now if you really need it. From my experience it gives from 3% to 10% performance wins. In ClickHouse it gave exactly 4% performance win:

It’s up to you to decide if you are able to trade the compile time and binary size for extra several percent of performance.
- A bit tricky one: Use libcxx as a standard library and define the macros
_LIBCPP_ABI_ENABLE_UNIQUE_PTR_TRIVIAL_ABI,_LIBCPP_ABI_ENABLE_SHARED_PTR_TRIVIAL_ABI
In C++, unfortunately, smart pointers come with an additional cost, for example:
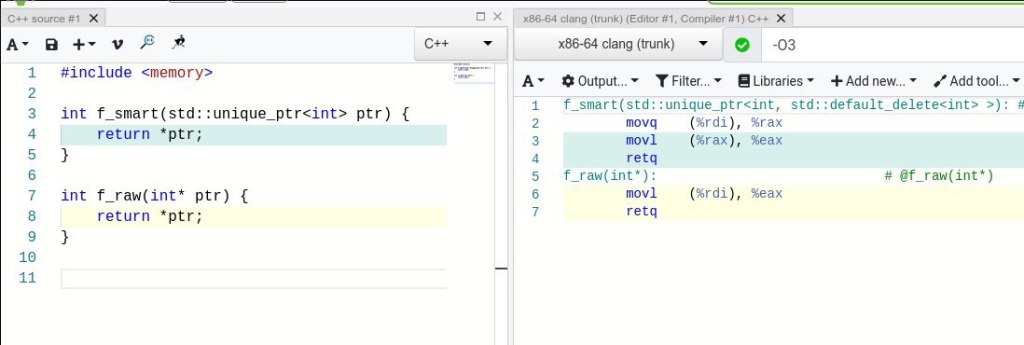
In SysV ABI it is said, that if a C++ class has a non-trivial destructor or assignment operator then it should be passed by an invisible pointer. Because of that smart pointers are not so cheap. You can try to change it by assigning the trivial ABI to these pointers and Google added the macro option in libcxx to do this. Some consequences of that will be:
The last failure is a bit more interesting, in order to guarantee the triviality, unfortunately, you need to call the destructor in a bit different way. Currently, the following would “work” because the argument to run_worker() is deleted at the end of func() With the new calling convention, it will be deleted at the end of run_worker(), making this an access to freed memory.
Google saw 1.6% performance gains fleetwide and only several failures (out of hundreds of millions of code) which can be easily fixed. Also, the binary sizes reduced by several percent.
Overall I haven’t tried these macros yet in ClickHouse for a couple of failures but switching to libcxx itself gave 2% performance boost:

In total, I believe you can find from 5 to 15 performance boost easily by adopting the correct options, fresh libraries and adequate code options.
I don’t recommend -ffast-math if you are not sure in your precision calculations but in some scientific heavy computing programs I’ve seen that to find another percent. Also, I don’t recommend -Ofast for the same reasons: the optimizations can be unsafe there. I read not so long ago an article Spying on the floating point behavior of existing, unmodified scientific applications which only proves that unsafe operations with floats do happen in any sophisticated software.
Conclusion
Of course, nothing will help you if you use quadratic algorithms instead of linear and the best performance optimizations come from algorithmic approaches rather than the compiler ones. However, I found myself telling about these options to several teams and people so that I decided to put the knowledge right there for a broader audience to know. What to use, how to trade compile time vs run time is up to you but always think about the time of the developers, ease of migrations, usage, etc.
For GCC I haven’t found such flexibility but possibly some of them are hidden in the documentation under the --param option. I personally believe that happens because people don’t usually tell or try them relying on the compiler a lot like a black box and a source of truth. However, as in every complex system, the truth is more complicated (and boring) and compiler engineers are also not the ones who are writing perfect code or are able to tell about their research to massive public.
I personally feel that LLVM infrastructure is going to stick with me for quite some time because it is just easier, more modern, and provides the ability to move faster than GCC where I am always lost to find the code I need.
