Today I present a big effort from my side to publish miniselect — generic C++ library to support multiple selection and partial sorting algorithms. It is already used in ClickHouse with huge performance benefits. Exact benchmarks and results will be later in this post and now let’s tell some stories about how it all arose. I publish this library under Boost License and any contributions are highly welcome.
It all started with sorting
While reading lots of articles, papers, and posts from Hacker News, I found it pretty funny each several months new “shiny”, “fastest”, “generic” sorting algorithms to come or remembered from old papers such as the recent paper on learned sorting, Kirkpatrick-Reisch sort or pdqsort. It is that we are essentially 65+ years into writing sorting algorithms, and we still find improvements. Shouldn’t sorting items be a “solved” problem by now? Unfortunately, not. New hardware features come, we find that sorting numbers can be actually done faster than best comparison 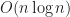
Huge competition is still going on in sorting algorithms and I believe we are not near the optimal sorting and learned sorting looks like the next step. But it uses the fundamental fact that no one expects sorting to be completed in a couple of passes and we can understand something about data during first array passes. We will understand why it matters later.
My favorite general sorting is pdqsort, it proves to be currently the best general sorting algorithm and it shows a significant boost over all standard sorts that are provided in C++. It is also used in Rust.
Selection and Partial Sorting
Nearly a couple of months ago I started thinking about a slightly different approach when it comes to sorting — partial sorting algorithms. It means that you don’t need to sort all 

ORDER BY LIMIT N and N is often small, from 1-10 to ideally couple of thousands, bigger values still happen but rare. And, oh god, how little engineering and theoretical research has been done there compared to full sorting algorithms. In fact, the question of specifically finding 
QuickSelect
This is almost the very first algorithm for finding the 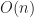
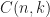
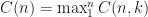
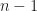


If assuming by induction that 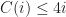

Bad news is that the worst case will still be 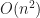
In that sense that algorithm provides lots of pivot “strategies” that are used nowadays, for example, picking pivot as a 
std::nth_element from libcxx — choose the middle out out of ![A[0], A[n/2], A[n - 1]](https://s0.wp.com/latex.php?latex=A%5B0%5D%2C+A%5Bn%2F2%5D%2C+A%5Bn+-+1%5D&bg=FFFFFF&fg=181818&s=0&c=20201002)
I decided to visualize all algorithms I am going to talk about today, so quickselect with a median of 3 strategy on random input looks something like this:

And random pivot out of 3 elements works similar

For a strategy like libcxx (C++ llvm standard library) does, there are quadratic counterexamples that are pretty easy to detect, such patterns also appear in real data. The counterexample looks like that:

This is definitely quadratic. By the way, this is perfectly ok with the C++ standard wording as it says:

Median of Medians
For a long time, computer scientists thought that it is impossible to find medians in worst-case linear time, however, Blum, Floyd, Pratt, Rivest, Tarjan came up with BFPRT algorithm or like sometimes it is called, median of medians algorithm.
Median of medians algorithm: Given array 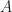

- Group the array into
groups of size 5 and find the median of each group. (For simplicity, we will ignore integrality issues.)
- Recursively, find the true median of the medians. Call this
.
- Use
- Recurse on the appropriate piece.
When we find the median 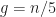

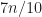
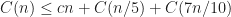
If we appropriately build the recurse tree we will see that

This is the geometric series with 

Actually, this constant 10 is really big. For example, if we look a bit closer, 
- Use three comparisons and shuffle around the numbers so that
, and
.
- If
, then the problem is fairly easy. If
, the median value is the smaller of
and
. If not, the median value is the smaller of
and
.
- So
. If
, then the solution is the smaller of
So that maximum 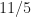

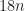

HeapSelect
Another approach to finding 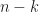
std::partial_sort works that way (with additional heap sorting of the first heap). It shows good results for very small 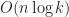

IntroSelect
As the previous algorithm is not very much practical and QuickSelect is really good on average, in 1997 “Introspective Sorting and Selection Algorithms” from David Musser came out with a sorting algorithm called “IntroSelect”.
IntroSelect works by optimistically starting out with QuickSelect and only switching to MedianOfMedians if it recurses too many times without making sufficient progress. Simply limiting the recursion to constant depth is not good enough, since this would make the algorithm switch on all sufficiently large arrays. Musser discusses a couple of simple approaches:
- Keep track of the list of sizes of the subpartitions processed so far. If at any point
recursive calls have been made without halving the list size, for some small positive
- Sum the size of all partitions generated so far. If this exceeds the list size times some small positive constant
This algorithm came into libstdcxx and guess which strategy was chosen? Correct, none of them. Instead, they try 

PDQSelect
Now that most of the known algorithms come to an end 😈, we can start looking into something special and extraordinary. And the first one to look at is pdqselect which comes pretty straightforward from pdqsort, the algorithm is basically QuickSelect but with some interesting ideas on how to choose an appropriate pivot:
- If there are
elements, use insertion sort to partition or even sort them. As insertion sort is really fast for a small amount of elements, it is reasonable
- If it is more, choose
- If there are less or equal than 128 elements, choose pseudomedian (or “ninther”, or median of medians which are all them same) of the following 3 groups:
- begin, mid, end
- begin + 1, mid – 1, end – 1
- begin + 2, mid + 1, end – 2
- If there are more than 128 elements, choose median of 3 from begin, mid, end
- If there are less or equal than 128 elements, choose pseudomedian (or “ninther”, or median of medians which are all them same) of the following 3 groups:
- Partition the array by the chosen pivot with avoiding branches:
- The partition is called bad if it splits less than
elements
- If the total number of bad partitions exceeds
, use
std::nth_elementor any other fallback algorithm and return - Otherwise, try to defeat some patterns in the partition by (sizes are l_size and r_size respectively):
- Swapping begin, begin + l_size / 4
- Swapping p – 1 and p – l_size / 4
- And if the number of elements is more than 128
- begin + 1, begin + l_size / 4 + 1
- begin + 2, begin + l_size / 4 + 2
- p – 2, p – l_size / 4 + 1
- p – 3, p – l_size / 4 + 2
- Do the same with the right partition
- The partition is called bad if it splits less than
- Choose the right partition part and repeat like in QuickSelect

Median Of Ninthers or Alexandrescu algorithm
For a long time, there were no practical improvements in finding
There are 2 key ideas:
- We now find the pseudomedian (or ninther, or median of medians which are all the same) of 9 elements as it was done similarly in pdqsort. Use that partition when


- Introduce MedianOfMinima for
. MedianOfMedians computes medians of small groups and takes their median to find a pivot approximating the median of the array. In this case, we pursue an order statistic skewed to the left, so instead of the median of each group, we compute its minimum; then, we obtain the pivot by computing the median of those groupwise minima.

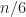
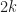



Turns out it is a better algorithm than all above (except it did not know about pdqselect) and shows good results. My advice that if you need a deterministic worst-case linear algorithm this one is the best (we will talk about a couple of more randomized algorithms later).

Small k
All these algorithms are good and linear but they require lots of comparisons, like, minimum 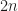


For finding a minimum you just compare linearly the winner with all others and basically the second place can be anyone who lost to the winner, so we need to compare them within each other. Unfortunately, the winner may have won linear number of others and we will not get the desired amount of comparisons. To mitigate this, we need to make a knockout tournament where the winner only plays
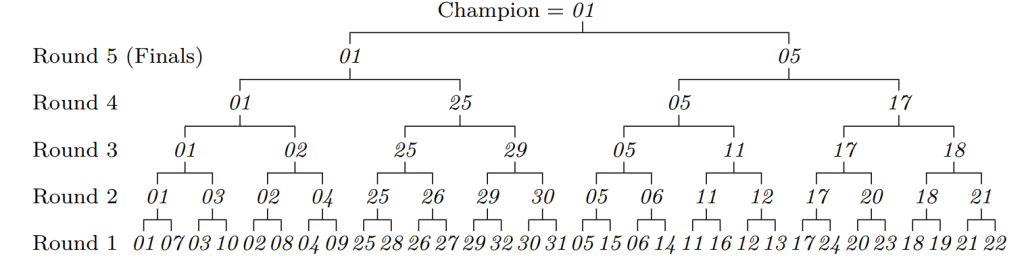
And all we need to do next is to compare all losers to the winner

And any of them can be the second. And we use only 
What can we do to find the third and other elements? Possibly not optimal in comparison count but at least not so bad can follow the strategy:
First set up a binary tree for a knockout tournament on 



It will give us the estimation of 
At that time my knowledge of selection algorithms ended and I decided to address one known guy.

In The Art of Computer Programming, Volume 3, Sorting and Searching I read almost 100-150 pages in order to understand what the world knows about minimal comparison sorting and selection algorithms and found a pretty interesting one called Floyd-Rivest algorithm. Actually, even Alexandrescu paper cites it but in an unusual way:

Floyd-Rivest algorithm
This algorithm is essentially the following
The general steps are:
- Select a small random sample
of size
from the array.
- From
and
, such that
(essentially they take
and
). These two elements will be the pivots for the partition and are expected to contain the
- Using
- Partition the remaining elements in the array by comparing them to u or v and placing them into the appropriate set. If
- Apply the algorithm recursively to the appropriate set to select the
Then in 2004 it was proven that this method (slighly modified in bound selection) will have 

This algorithm tries to find the appropriate subsamples and proves that the


Yet the worst case of the algorithm is still
For small 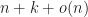

What it resulted in
So I decided to code all these algorithms with the C++ standard API and to test against each other and possibly submit to something performance heavy as DBMS for ORDER BY LIMIT N clauses.
I ended up doing miniselect library. For now, it is header-only but I don’t guarantee that in the future, it contains almost all algorithms except the tournament one which is very hard to do in the general case.
I tested on Intel(R) Core(TM) i5-4200H CPU @ 2.80GHz (yeah, a bit old, sorry). We are going to find median and 1000th elements out of 

- Ascending
- Descending
- Median3Killer which I described above
- PipeOrgan: half of the values are ascending, the other half is descending
- PushFront: ascending but the smallest element added to the end
- PushMiddle: ascending but the middle element added to the end
- Random
- Random01: random only with values 0 and 1
- Shuffled16: random only with 16 overall values
You can see other values also here.


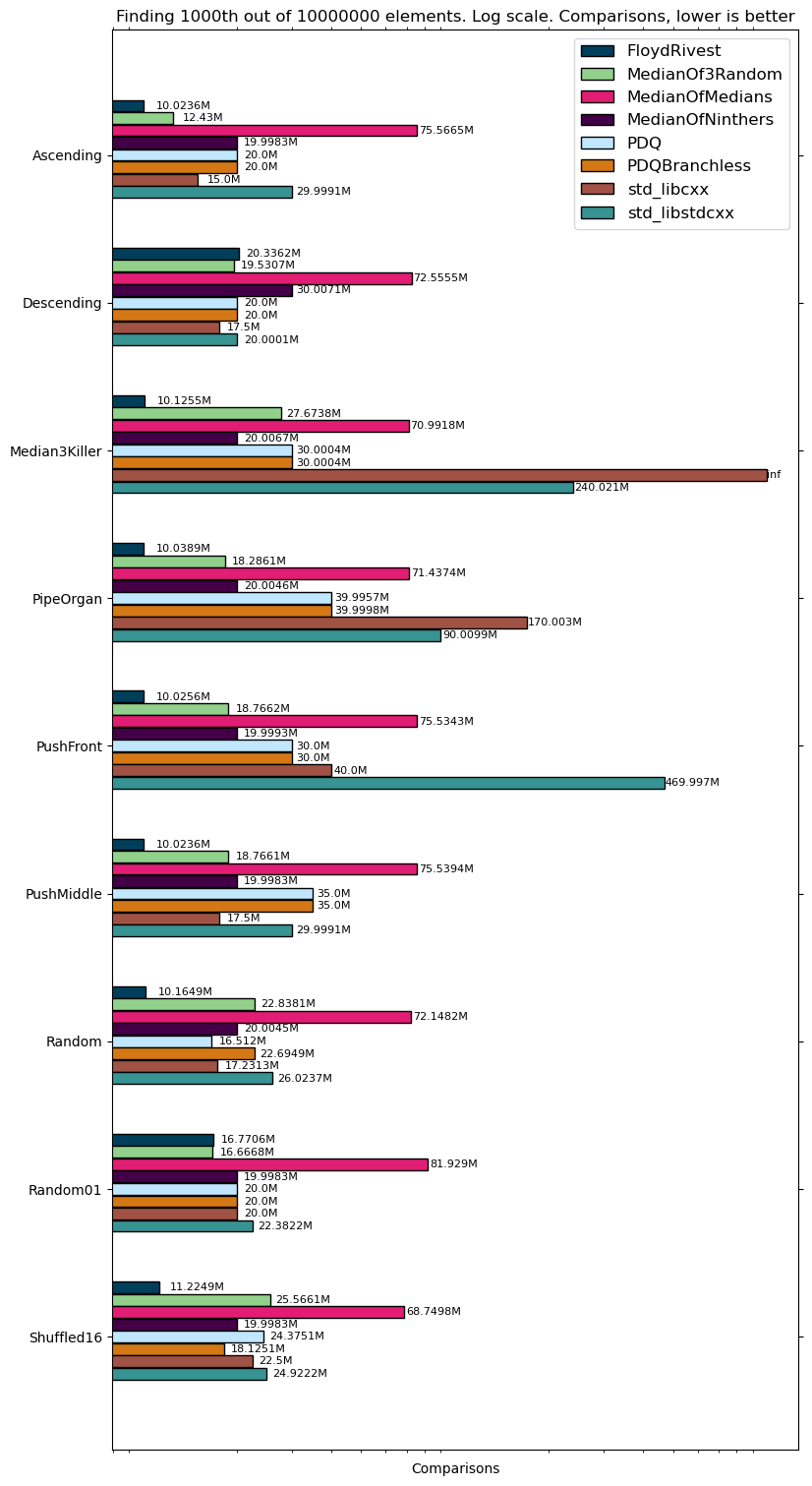

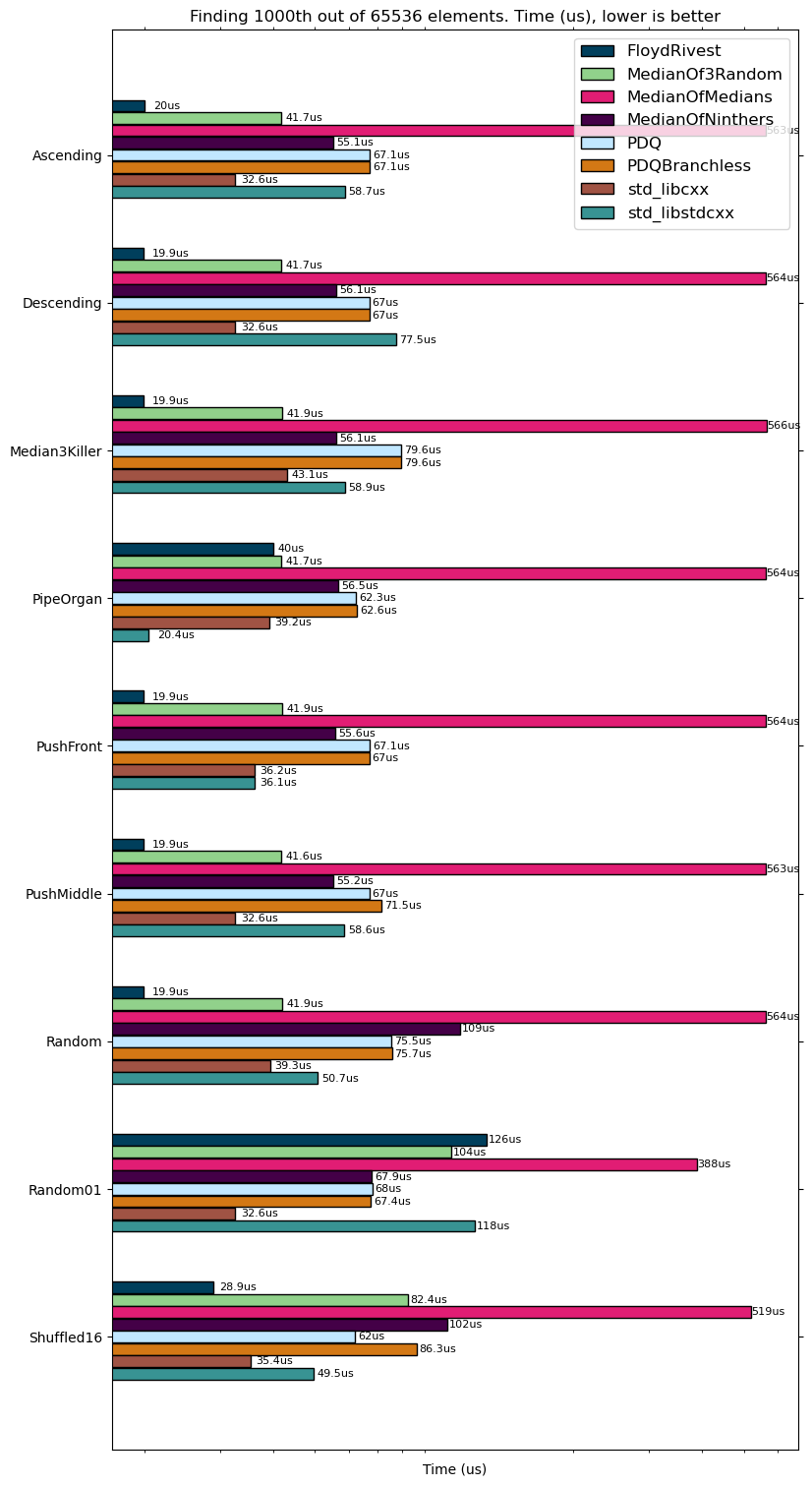


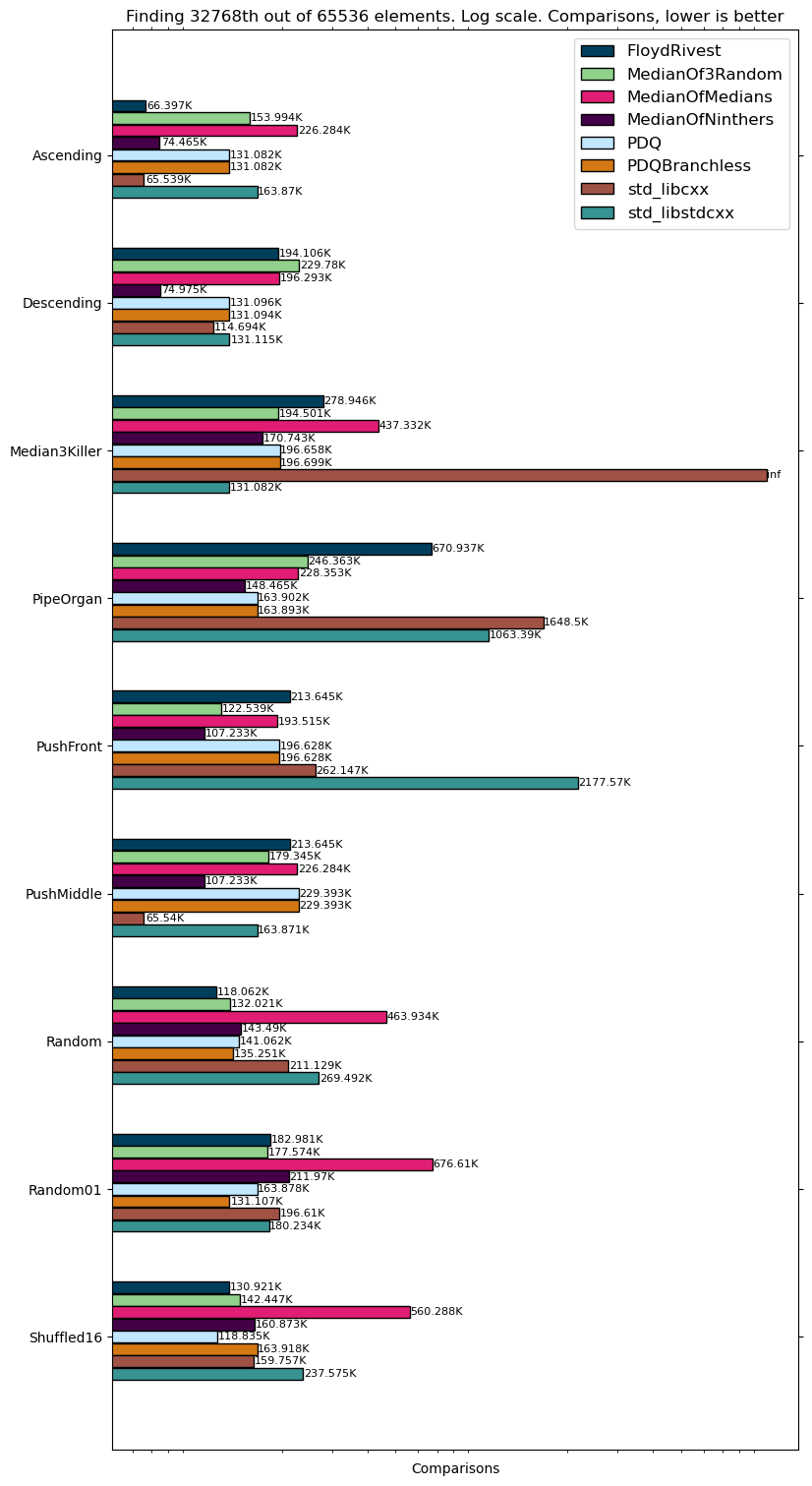
As you see, Floyd-Rivest outperforms in time all other algorithms and even Alexandrescu in most of the cases. One downside is that Floyd-Rivest performs worse on data where there are many equal elements, that is expected and probably can be fixed as it is pointed out in Kiwiel’s paper.
Real World
This effort also resulted in a patch to ClickHouse where we got the following benchmarks:
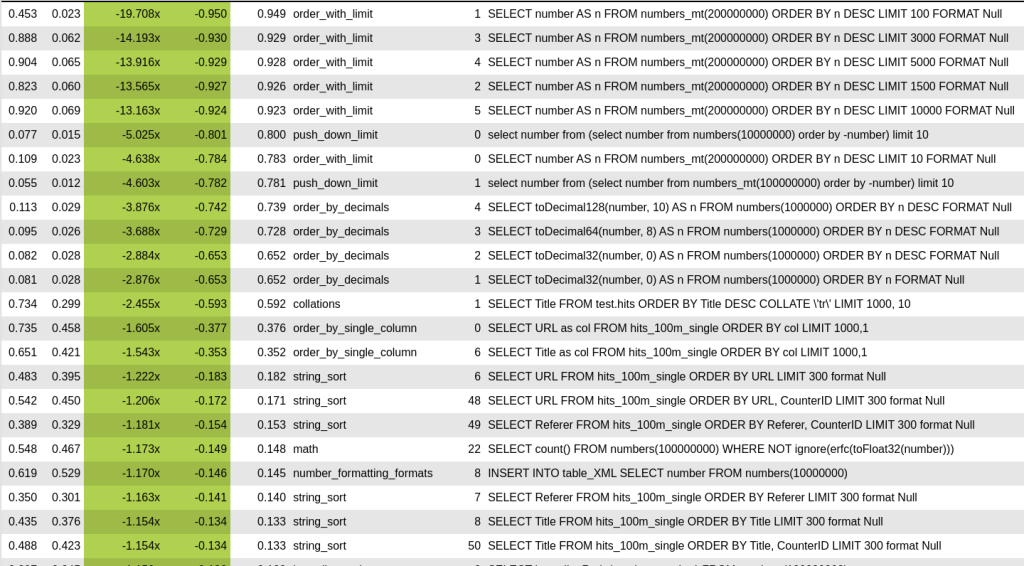
As you see, most of the queries have ORDER BY LIMIT N. Topmost queries were significantly optimized because std::partial_sort works worst when the data is descending, real-world usage as you can see in string_sort benchmarks was optimized by 10-15%. Also, there were many queries that have been optimized by 5% where sorting is not the bottleneck but still, it is nice. It ended up with a 2.5% overall performance boost across all queries.
Other algorithms showed worse performance and you can see it from the benchmarks above. So, now Floyd-Rivest is used in production, and for a good reason. But, of course, it does not diminish the results of Mr. Alexandrescu and his contributions are very valuable when it comes to determinism and worst case.
Library
I publish miniselect under Boost License for everybody to use and adjust to the projects. I spent several days in the last week trying to make it work everywhere (except Windows for now but it should be good). We support C++11 and further with GCC 7+ and Clang 6+. We carefully test the algorithms for standard compliance, with fuzzing, sanitizers, etc. Fuzzing managed to find bugs that I thought only at the last moment so it really helps.
If you want to use it, please read the API but it should be an easy sed/perl/regex replacement with zero issues except for the ties between elements might resolve in a different way, however, C++ standard says it is ok and you should not rely on that.
Any contributions and other algorithms that I might miss are highly welcome, I intend to get this library as a reference to many implementations of selection algorithms so that the users can try and choose the best options for them. (Should I do the same for sorting algorithms?)
Conclusion
This was a long story of me trying to find the solutions to the problems that were puzzling me for the past month or so. I probably read 300+ pages of math/algorithms/discussions/forums to finally find everything that the world knows about it and to make it work for real-world applications with huge performance benefits. I think I can come up with something better in a long term after researching this stuff for a while longer but I will let you know in this blog if anything arises 🙂
References I find useful (together with zero mentions in the post)
- Selection Algorithms with Small Groups where the Median of Medians algorithms are a little bit twisted for groups of size 3 and 4 with linear time worst-case guarantee
- Understandable proof of second biggest element minimum comparisons bound
- On Floyd and Rivest’s SELECT algorithm by Krzysztof C. Kiwiel
- The Art of Computer Programming, Volume 3, Sorting and Searching, Chapter about Minimum-Comparison Sorting and Selection
- Original Floyd-Rivest paper
- Simple proof of a bit worse bound for Floyd-Rivest algorithm by Sam Buss
- Fast Deterministic Selection by Andrei Alexandrescu
- An efficient algorithm for the approximate median selection problem by S. Battiato, D. Cantone, D. Catalano and G. Cincotti
- An efficient implementation of Blum, Floyd, Pratt, Rivest, and Tarjan’s worst-case linear selection algorithm
- Selection from read-only memory and sorting with minimum data movement by J. Ian Munro, Venkatesh Raman
