When it comes to hashing, sometimes 64 bit is not enough, for example, because of birthday paradox — the hacker can iterate through random 
Division historically is the most complex operation on CPUs and all guidelines suggest avoiding the division at all costs.
At my job I faced an interesting problem of optimizing 128 bit division from abseil library in order to split some data across buckets with the help of 128 bit hashing (the number of buckets is not fixed for some uninteresting historical reasons). I found out that the division takes a really long time. The benchmarks from abseil on Intel(R) Xeon(R) W-2135 CPU @ 3.70GHz show some horrible results
Benchmark Time(ns) CPU(ns)
BM_DivideClass128UniformDivisor 13.8 13.8 // 128 bit by 128 bit
BM_DivideClass128SmallDivisor 168 168 // 128 bit by 64 bit150 nanoseconds for dividing the random 128 bit number by a random 64 bit number? Sounds crazy. For example, div instruction on x86-64 Skylake takes 76 cycles (also, for AMD processors it is much less), the division takes around 20-22ns.

In reality everything is slightly better because of pipeline execution and division has its own ALU, so if you divide something and do something else in the next instructions, you will get lower average latency. Still, 128 bit division cannot be 8x slower than 64 bit division. All latencies you can find in Agner Fog instruction table for most of the modern x86 CPUs. The truth is more complex and division latency can even depend on the values given.

Even compilers when dividing by some constants, try to use the reciprocal (or, the same as inverse in a ring) value and multiply the reciprocal and the value with some shifts afterwards
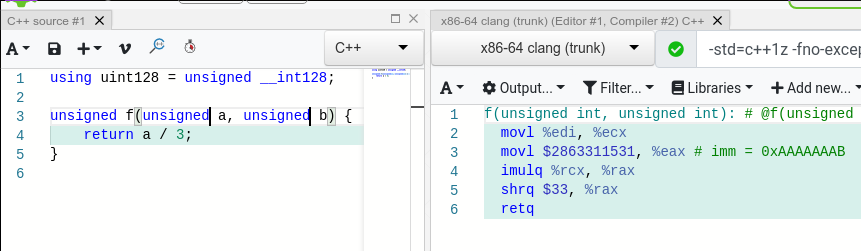
Overall, given the fact that only some sin, cos instructions cost more than division, division is one of the most complex instructions in CPUs and optimizations in that place matter a lot. My exact case was more or less general, maybe I was dividing 128 bit by 64 bit a bit more frequent. We are going to optimize the general case in LLVM.
We need to understand how 128 bit division is working through the compiler stack.
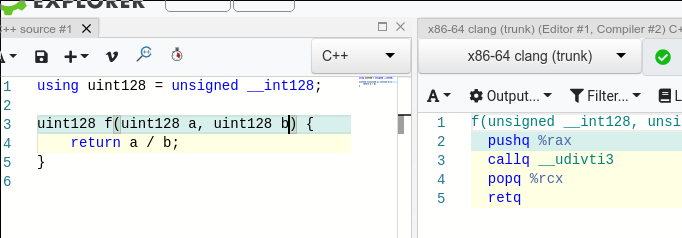
It calls __udivti3 function. Let’s first understand how to read these functions. In runtime libraries the modes of the functions are:
QI: An integer that is as wide as the smallest addressable unit, usually 8 bits.
HI: An integer, twice as wide as a QI mode integer, usually 16 bits.
SI: An integer, four times as wide as a QI mode integer, usually 32 bits.
DI: An integer, eight times as wide as a QI mode integer, usually 64 bits.
SF: A floating point value, as wide as a SI mode integer, usually 32 bits.
DF: A floating point value, as wide as a DI mode integer, usually 64 bits.
TI: An integer, 16 times as wide as a QI mode integer, usually 128 bits.So, udivti3 is an unsigned division of TI (128 bits) integers, last ‘3′ means that it has 3 arguments including the return value. Also, there is a function __udivmodti4 which computes the divisor and the remainder (division and modulo operation) and it has 4 arguments including the returning value. These functions are a part of runtime libraries which compilers provide by default. For example, in GCC it is libgcc, in LLVM it is compiler-rt, they are linked almost in every program if you have the corresponding toolchain. In LLVM, __udivti3 is a simple alias to __udivmodti4.
__udivmodti4 function was written with the help of Translated from Figure 3-40 of The PowerPC Compiler Writer's Guide. After looking at it here, it looks like this was written long time ago and things have changed since then

First of all, let’s come up with something easy, like shift-subtract algorithm that we have been learning since childhood. First, if divisor > dividend, then the quotient is zero and remainder is the dividend, not an interesting case.
The algorithm is easy, we align the numbers by their most significant bits, if dividend is more than divisor, subtract and add 1 to the output, then shift by 1 and repeat. Some sort of animation can be seen like that:

For 128 bit division it will take at most 128 iterations in the for loop. Actually, the implementation in LLVM for loop is a fallback and we saw it takes 150+ns to complete it because it requires to shift many registers because 128 bit numbers are represented as two registers.
Now, let’s dive into the architecture features. I noticed that while the compiler generates the divq instructions, it frees rdx register

In the manual they say the following

divq instruction provides 128 bit division from [%rdx]:[%rax] by S. The quotient is stored in %rax and the remainder in %rdx. After some experimenting with inline asm in C/C++, I figured out that if the result does not fit in 64 bits, SIGFPE is raised. See:
Compilers don’t use this instruction in 128 bit division because they cannot know for sure if the result is going to fit in 64 bits. Yet, if the high 64 bits of the 128 bit number is smaller than the divisor, the result fits into 64 bits and we can use this instruction. As compilers don’t generate divq instruction for their own reasons, we would use inline asm for x86-64.
What to do if the high is not less than the divisor? The right answer is to use 2 divisions because
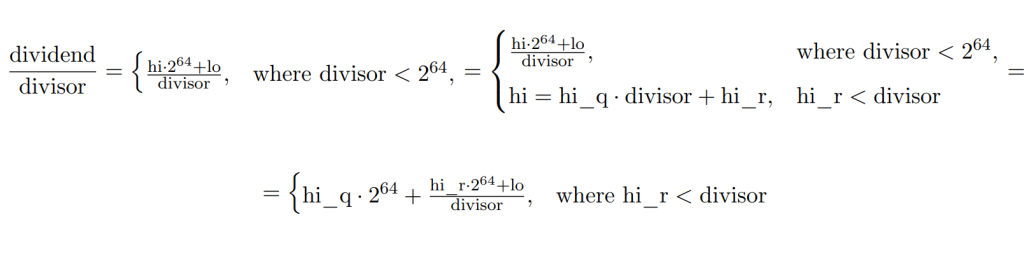
So, first we can divide hi by divisor and then {hi_r, lo} by divisor guaranteeing that hi_r is smaller than divisor and thus the result is smaller than 
After that the benchmarks improved significantly
Benchmark Time(ns) CPU(ns)
BM_DivideClass128UniformDivisor 11.9 11.9
BM_DivideClass128SmallDivisor 26.6 26.6Only 26.6ns for small divisors, that’s a clear 6x win.
Then there are multiple choices to do next but we know that both dividend and divisor have at least one bit in their high registers and the shift-subtract algorithm will have at most 64 iterations. Also the quotient is guaranteed to fit in 64 bits, thus we can use only the low register of the resulting quotient and save more shifts in the shift-subtract algorithm. That’s why the uniform divisor slightly improved.
One more optimization to do in shift-subtract algorithm is to remove the branch inside the for loop (read carefully, it should be understandable).
In the end, it gives 0.4ns more for uniform 128 bit divisor.
And finally I believe that’s one of the best algorithm to divide 128 bit by 128 bit numbers. From statistics, the case when the divisor is 64 bit is worth optimizing and we showed that additional checks on the high register of divisor has its own advantages and expansion of the invariants. Now let’s see what other libraries perform in that case.
LibDivide
Libdivide is a small library targeting fast division, for example, if you divide by some fixed number a lot of times, there are techniques that can precalculate reciprocal and then multiply by it. Libdivide provides a very good interface for such optimizations. Even though, it has some optimizations regarding 128 bit division. For example, function libdivide_128_div_128_to_64 computes the division 128 bit number by 128 bit number if the result fits in 64 bits. In the case where both numbers are more or equal to

With the instruction that produces the 64 bit result when the divisor is 128 bit result we can compute
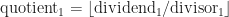
Then we compute

It cannot overflow because 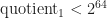
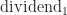


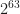


Now we want to show that 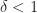
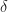




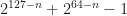

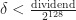
Unfortunately, these corrections increase the latency of the benchmark pretty significant
Benchmark Time(ns) CPU(ns)
BM_DivideClass128UniformDivisor<LibDivideDivision> 26.3 26.3
BM_RemainderClass128UniformDivisor<LibDivideDivision> 26.2 26.2
BM_DivideClass128SmallDivisor<LibDivideDivision> 25.8 25.8
BM_RemainderClass128SmallDivisor<LibDivideDivision> 26.3 26.3So I decided to drop this idea after I’ve tried this.
GMP
GMP library is a standard GNU library for long arithmetic. They also have something for 128 bit by 64 bit division and in my benchmark the following code worked
It divides the two limbs by a uint64_t and provides the result. Unfortunately, the latency is much higher than expected, also does not work
Benchmark Time(ns) CPU(ns)
BM_DivideClass128UniformDivisor<GmpDivision> 11.5 11.5
BM_RemainderClass128UniformDivisor<GmpDivision> 10.7 10.7
BM_DivideClass128SmallDivisor<GmpDivision> 47.5 47.5
BM_RemainderClass128SmallDivisor<GmpDivision> 47.8 47.8 Conclusion
In the end I’ve tried several method of 128 bit division and came up with something that is the fastest among popular alternatives. Here is the full code for benchmarks, though it is quite hard to install, maybe later I will provide an easy version of installation. The final benchmarks are
Benchmark Time(ns) CPU(ns)
---------------------------------------------------------------------
BM_DivideClass128UniformDivisor<absl::uint128> 13.7 13.7
BM_RemainderClass128UniformDivisor<absl::uint128> 14.0 14.0
BM_DivideClass128SmallDivisor<absl::uint128> 169 169
BM_RemainderClass128SmallDivisor<absl::uint128> 153 153
BM_DivideClass128UniformDivisor<LLVMDivision> 12.6 12.6
BM_RemainderClass128UniformDivisor<LLVMDivision> 12.3 12.3
BM_DivideClass128SmallDivisor<LLVMDivision> 145 145
BM_RemainderClass128SmallDivisor<LLVMDivision> 140 140
**BM_DivideClass128UniformDivisor<MyDivision1> 11.6 11.6**
**BM_RemainderClass128UniformDivisor<MyDivision1> 10.7 10.7**
**BM_DivideClass128SmallDivisor<MyDivision1> 25.5 25.5**
**BM_RemainderClass128SmallDivisor<MyDivision1> 26.2 26.2**
BM_DivideClass128UniformDivisor<MyDivision2> 12.7 12.7
BM_RemainderClass128UniformDivisor<MyDivision2> 12.8 12.8
BM_DivideClass128SmallDivisor<MyDivision2> 36.9 36.9
BM_RemainderClass128SmallDivisor<MyDivision2> 37.0 37.1
BM_DivideClass128UniformDivisor<GmpDivision> 11.5 11.5
BM_RemainderClass128UniformDivisor<GmpDivision> 10.7 10.7
BM_DivideClass128SmallDivisor<GmpDivision> 47.5 47.5
BM_RemainderClass128SmallDivisor<GmpDivision> 47.8 47.8
BM_DivideClass128UniformDivisor<LibDivideDivision> 26.3 26.3
BM_RemainderClass128UniformDivisor<LibDivideDivision> 26.2 26.2
BM_DivideClass128SmallDivisor<LibDivideDivision> 25.8 25.8
BM_RemainderClass128SmallDivisor<LibDivideDivision> 26.3 26.3MyDivision1 is going to be upstreamed in LLVM, MyDivision2 will be the default version for all non x86-64 platforms which also has a solid latency, much better than the previous one.
Future Work
However, benchmarks are biased in the uniform divisor case because the distance between most significant bits in the dividend and divisor falls exponentially and starting from 10-15, the benchmark becomes worse rather than libdivide approach.
I also prepared some recent research paper patch in https://reviews.llvm.org/D83547 where the reciprocal is computed beforehand and then only some multiplication happens. Yet, with the cold cache of the 512 byte lookup table it is worse than the already submitted approach. I also tried just division by 

Also, subscribe to my Twitter https://twitter.com/Danlark1 🙂

Good work!
Somehow many of my personal projects involve integer division and hence I have spent a lot of time writing my own optimized integer division functions because GCC’s and LLVM’s implementations were good enough for me. So it is great to see that you have upstreamed your improvements to LLVM. Integer division has been a pain for me over the past 20 years, but over the past 2 years the first CPUs (i.e. IBM POWER9, Intel Cannon Lake) have appeared on the market with tremendously better integer division performance. For this reason I am reasonably optimistic that by the end of this decade integer division performance will be fixed problem.
LikeLiked by 1 person
Many years ago I faced the same scale of birthday paradox in Varnish Cache.
After looking at the various options, I chose SHA256 as my hash function, trading a little bit of speed, for never having to think about that part of the code ever again.
LikeLike
“Still, 128 bit division cannot be 8x slower than 64 bit division.”
That sentence is backwards, right? 64-bit actually has the higher latency in that chart.
LikeLike
No, the latency for 64 bit division is around 20-20ns but for 128 bit is 168ns which gives us 8x
LikeLike
Is the table mislabeled then? Are we reading the same thing? The table right below the third paragraph says:
13.8 // 128 bit by 128 bit
168 // 128 bit by 64 bit
LikeLike
Is there any plan to commit those codes to libgcc?
LikeLike
To be completely honest, it looks like libgcc has a very similar implementation when I disassembled it, also I was not able to find the entry point in the repository and I eventually gave up
LikeLike
Oh, i see.
BTW, it’s in libgcc/libgcc2.c, with the name__udivmoddi4 which would be replace by preprocessor as __udivmodti4.
libgcc use udiv_qrnnd which is similar as your Divide128Div64To64.
LikeLike
For “big” divisors, you optimized but not the general case.
See https://skanthak.homepage.t-online.de/integer.html for a faster implementation.
Also see https://skanthak.homepage.t-online.de/division.html for the shortcomings of the implementation for non-AMD64 machines.
And finally see https://skanthak.homepage.t-online.de/msvc.html#comparision for benchmarks of various implementations of 64-bit by 64-bit division for 32-bit Intel processors, including those used by LLVM’s Compiler-RT library.
LikeLike
Apropos “branch-free”: EVERY self-respecting optimizing C compiler SHOULD translate a sequence
X <= Z) Y -= Z; X += 1;
into machine code equivalent to the following AMD64 instructions (assuming that X lives in %rcx, Y in %rdx:%rax, Z in %r8:%r9, and that %r10:%r11 are scratch):
MOVQ %rax,%r10; MOVQ %rdx,%r11; SUBQ %rax,%r9; SBBQ %rdx,%r8; CMOVB %r10,%rax; CMOVB %r11,%rdx; CMC; ADCQ %rcx,%rcx
LikeLike
From your first paragraph, you suggest that iterating over 2^32 random elements can find a collision with some probability, but that probability is very low, 2^-32 (ie, 1 in 4 billion that you’d get a collision). To get 50% chance, you’d need to iterate through 2^63 random elements. Do you consider 2^-32 a manageable attack?
LikeLike
The collision is between any two of the 2^32 elements, not between a fixed target and the 2^32 elements. This changes the expected probably very significantly.
LikeLike
You don’t need a division to divide a hash equally* among k buckets, even with k not fixed. You can use the same approach as for generating a (biased) random number in a range:
*This approach is of course biased if k isn’t a power of two, but all solutions will be.
LikeLike