TL;DR; We are changing std::sort in LLVM’s libcxx. That’s a long story of what it took us to get there and all possible consequences, bugs you might encounter with examples from open source. We provide some benchmarks, perspective, why we did this in the first place and what it cost us with exciting ideas from Hyrum’s Law to reinforcement learning. All changes went into open source and thus I can freely talk about all of them.
This article is split into 3 parts, the first is history with all details of recent (and not so) past of sorting in C++ standard libraries. Second part is about what it takes to switch from one sorting algorithm to another with various bugs. The final one is about the implementation we have chosen with all optimizations we have done.
Chapter 1. History
Sorting algorithms have been extensively researched since the start of computer science.1 Specifically, people tried to optimize the number of comparisons on average, in the worst case, in certain cases like partially sorted data. There is even a sorting algorithm that is based on machine learning2 — it tries to predict the position where the elements should go with pretty impressive benchmarks! One thing is clear—sorting algorithms do evolve even now with better constant factors and reduced number of comparisons made.
In every programming language, sorting calls exist and it’s up to the library to decide which one to use, we’ll talk about different choices in languages later. There are still debates over which sorting is the best on Hackernews3, papers4, repos5.
As Donald Knuth said
It would be nice if only one or two of the sorting methods would dominate all of the others, regardless of application or the computer being used. But in fact, each method has its own peculiar virtues. […] Thus we find that nearly all of the algorithms deserve to be remembered, since there are some applications in which they turn out to be best.
— Donald Knuth, The Art Of Computer Programming, Volume 3
C++ history
std::sort has been in C++ since the invention of so-called “STL” by Alexander Stepanov9 and C++ standard overall got an interesting innovation back then called “complexity”. At the time the complexity was set to being 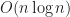
How was really the first std::sort implemented?
It used a simple quicksort with a median of 3 (median from (first, middle, last) elements). Once the recursion hits less than 16 elements, it bails out and at the end uses insertion sort as it is believed to work faster for small arrays.
You can see the last stage where it tries to “smooth out” inaccurate blocks of size 16.
A minor problem with quicksort
Well, that’s definitely true that quicksort has

This actually gives us an opportunity to self-modify the array, or, in other words, make decisions along the way the comp function is called, and introduce a worst time complexity on any data. The code below will make sense in a little while:
If we consider any quick sort algorithm with the following semantics:
- Find some pivot
among
elements (constant number)
- Partition by pivot, recurse on both sides
“gas” value represents unknown, infinity, the value is set to the left element only when two unknown elements are compared, and if one element is gas, then it is always greater.
At the first step you pick some pivot among at most 
At step 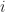

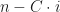
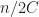
If we run this code against the original STL10, we clearly are having a quadratic number of comparisons.
No matter which randomization we are going to introduce, even quicksort implementation of std::sort is quadratic on average (with respect to arbitrary comparator) and implementation technically is not compliant.
The example above does not try to prove something and is quite artificial, even though there were some problems with the wording in the standard regarding “average” case.
Moving on with quadratic behavior
Quicksort worst case testing was first introduced by Douglas McIlroy11 in 1998 and called “Antiquicksort”. In the end it influenced the decision to move std::sort complexity being worst case
Well, however there is more to the story.
Are modern C++ standard libraries actually compliant?
There are not so many places C++ standard specifies the wording “on average“. One more example is std::nth_element call.
What is std::nth_element?
You might guess it finds the nth element in the range. More specifically std::nth_element(first, nth, last, comp) is a partial sorting algorithm that rearranges elements in a range such that:
- The element pointed at by
nthis changed to whatever element would occur in that position if[first, last)were sorted. - All of the elements before this new
nthelement are less than or equal to the elements after the newnthelement.
You can see that the complexity still states “on average“.

This decision was in place due to the existing quickselect12 algorithm. However, this algorithm is susceptible to the same trickery for both GNU and LLVM implementations.

For LLVM/clang version it’s obviously degrading to quadratic behavior, for GNU version 
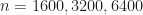

However, for finding nth element there are not so many worst case linear algorithms, one of them is median of medians16 which has a really bad constant. It took us around 20 years to find something really appropriate, thanks to Andrei Alexandrescu14 . My post on selection algorithms discussed that quite extensively but got too little attention in my humble opinion 🙂 (and it has an implementation from Andrei as well!). We found great speedups on real data for real SQL queries of type SELECT * from table ORDER BY x LIMIT N.
What happened to std::sort?
It started to use Introspective Sort, or, simply, introsort, upon too many levels of quicksort, more specifically 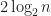
Here is the worst case sorting introsort for GNU implementation:
LLVM history
When LLVM tried to build C++0x version of STL, Howard Hinnant made a presentation6 on how it all was going with the implementation. Back then we recognized some really interesting benchmarks and more and more benchmarked sorts on different data patterns.

That gave us one interesting thought when we found this slide on what makes a sorting successful and efficient. Clearly not all data is random and some patterns happen in prod, how important is it to balance or recognize it?
For example even at Google as we use lots of protobufs, there are frequent calls to std::sort which come from the proto library7 which sorts all tags of fields presented in the message:
It makes a first quite important point: we need to recognize “almost sorted” patterns as they do happen. Obvious cases are ascending/descending, some easy mixes of those like pipes, and multiple consecutive increasing or decreasing runs. TL;DR; we did not do a very good job here but most modern algorithms do recognize quite obvious ones.
Theory: presortedness
Presortedness was first formally described in8:

Condition 1 is a normalizer, condition 2 states that we should care only about comparisons and not elements, condition 3 shows that if you can sort a supersequence, you should be able to sort a subsequence in fewer amount of comparisons, condition 4 is an upper limit on sorted parts: you should be able to sort 
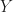

There are many existing presortedness measures like
- m01: 1 if not sorted, 0 if sorted. A pretty stupid one.
- Block: Number of elements in a sequence that aren’t followed by the same element in the sorted sequence.
- Mono: Minimum number of elements that must be removed from X to obtain a sorted subsequence, which corresponds to |X| minus the size of the longest non-decreasing subsequence of X.
- Dis: Maximum distance determined by an inversion.
- Runs: number of non-decreasing runs in X minus one.
- Etc
Some presortedness measures are better than others, meaning if there exists an algorithm is optimal towards some measure (optimality means number of comparisons 
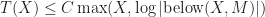
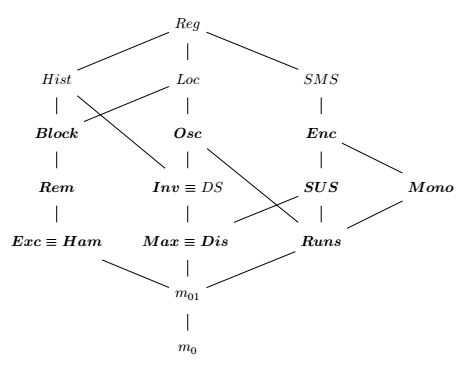
Unfortunately, among all measures above only Mono, Dis and Runs are linear time (others are 
Anyway, I guess you are tired of theory and let’s get to something more practical.
LLVM history continues
As LLVM libcxx was developed before C++11, the first version was also based on quicksort. What was the difference to the GNU sort?
The libcxx implementation handled a few particular cases specially. Collections of length 5 or less are sorted using special handwritten comparison based sortings.
Depending on the data type being sorted, collections of lengths up to 30 are sorted using insertion sort. Trivial types are easy to swap and assembly is quite good for them.
There is a special handling case for collections with most items being equal and for collections that are almost sorted. It tries to use insertion sort upon the limit of 8 transpositions: if during the outer loop we see more than 8 pair elements where 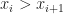
However, if you look at ascending inputs, you can see libstdcxx does lots of unnecessary work compared to libcxx sort which matters in practice. First is literally running 4.5 times faster!
Last distinction was that the median of 5 was chosen when the number of elements in a quicksort partition is more than 1000. No more differences, for me the biggest impact of this sort is in trying to identify common patterns which is not cheap but gets lots of benefits for real world cases.
When we changed libstdcxx to libcxx at Google, we saw significant improvements (dozens of percent) spent in std::sort. From then, the algorithm hasn’t been changed, and the usage has been growing.
Quadratic problem
Given LLVM libcxx was developed for C++03, the first implementation targeted on average case we talked about earlier. That has been addressed several times in the past, in 2014, 2017, 201817, 18.
In the end we managed to submit an improvement same as GNU library has with introsort. We add an additional parameter to the algorithm that indicates the maximum depth of the recursion the algorithm can go, then the remaining sequence on that path is sorted using heapsort. The number of partitions allowed is set to 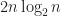
How many real world cases got there into heap sort?
We also were curious how much performance went into deep levels of quicksort and confirmed that one in several thousand of all std::sort calls got into the fallback heapsort.
That was slightly unusual to discover. It also did not show any statistically significant performance improvements, i.e. no obvious or significant quadratic improvements have been found. Quicksort is really working ok on real world data, however, this algorithm can be exploitable.
Chapter 2. Changing sorting is easy, isn’t it?
At first it looks easy to just change the implementation and win resources: sorting has order and, for example, if you sort integers, the API does not care about the implementation; the range should be just ordered correctly.
However, the C++ API can take compare functions, which may be for simplicity lambda functions. We will call them “comparators.” These can break our assumptions about sorting being deterministic in several ways. Sometimes I refer to this problem a.k.a. “ties can be resolved differently”.
More serious examples might involve SQL queries of type:
And we know that users like to write golden tests with queries of that sort. Even though nobody guarantees the order of equal elements, users do depend on that behavior as it might be buried down in code they have never heard of. That’s a classic example of Hyrum’s Law
With a sufficient number of users of an API,
it does not matter what you promise in the contract:
all observable behaviors of your system
will be depended on by somebody.
Hyrum Wright
Golden tests can be confusing if the diff is too big: are we breaking something or is the test too brittle to show anything useful to us? Golden tests are not a typical unit test because they don’t enforce any behavior. They simply let you know that the output of the service changed. There is no contract about the meaning of these changes; it is entirely up to the user to do whatever they want with this information.
When we tried to find all such cases, we understood it made the migration almost impossible to automate — how did we know these changes were the ones that the users wanted? In the end we learned a pretty harsh lesson that even slight changes in how we use primitives lead us to problems with goldens. It’s better if you use unit tests instead of golden ones or pay more attention to determinism of the code written.
Actually, about finding all Hyrum’s Law cases.
How to find all equal elements dependencies?
As equal elements are mostly indistinguishable during the compare functions (we found only a small handful of examples of comparators doing changes to array along the way), it is enough to randomize the range before the actual call to std::sort. You can figure out the probabilities and prove it is enough on your own.
We decided to submit such functionality into LLVM under debug mode20 for calls std::sort, std::nth_element, std::partial_sort.
Seeding techniques
We used ASLR (address space layout randomization)21 technique for seeding the random number generator, meaning static variables will be in random addresses upon the start of the program and we can use it as a seed. This provides the same stability guarantee within a run but not through different runs, for example, for tests to become flaky and eventually be seen as broken. For platforms which do not support ASLR, the seed is fixed during build. Using other techniques from header <random> was not possible as header <algorithm> recursively depended on <random> and in such a low level library, we implemented a very simple linear generator.
This randomization was enabled in a debug build mode as performance penalty might be significant for shuffling for all cases.
Partial vs nth danger
Also if you look closely at the randomization changes above, you may notice some difference between std::nth_element and std::partial_sort. That can be misleading.
std::partial_sort and std::nth_element have a difference in the meaning of their parameters that is easy to get confused. Both take 3 iterators:
begin– the beginning of the rangenthormiddle– the meaning (and name) of this parameter differs between these functionsend– the end of the range
For std::partial_sort, the middle parameter is called middle, and points right after the part of the range that should end up sorted. That means you have no idea which element middle will point to – you only know that it will be one of the elements that didn’t need to be sorted.
For std::nth_element, this middle parameter is nth. It points to the only element that will be sorted. For all of the elements in [begin, nth) you only know that they’ll be less than or equal to *nth, but you don’t know what order they’ll be in.
That means that if you want to find the 10th smallest element of a container, you have to call these functions a bit differently:

In the end, after dozens of runs of all tests at Google and with the help of a strong prevailing wind of randomness, we measured a couple of thousands of tests to be dependent on the stability of sorting and selection algorithms. As we also planned on updating sorting algorithms, this effort helped doing it gradually and sustainably.
All in all, it took us around a year to fix all of them.
Which failures will you probably discover?
Goldens
First of all, we, of course, discovered numerous failures regarding golden tests described above, that’s inevitable. From open source, you can try to look at ClickHouse22, 23, they also decided to introduce randomness described above.

Most changes will look like this by adjusting the right ordering and updating golden tests.
Unfortunately, golden tests might be quite sensitive to production workloads, for example, during streaming engine rollout — what if some instances produce slightly different results for the same shard? Or what if some compression algorithm by accident uses std::sort and compares the checksum from another service which hasn’t updated its implementation? That might cause checksum mismatch, higher error rate, users suffering and even data loss, and you cannot easily swap the algorithm right away as it can break production workloads in unusual ways. Hyrum’s Law at its best and worst. For example, we needed to inject in a couple of places old implementations to allow teams to migrate.
Oh, crap, determinism
Some other changes might require a transition from std::sort to std::stable_sort if determinism is required. We recommend writing a comment on why this is important as stable_sort guarantees that equal elements will be in the same order as before the sort.

Side note: defaults in other languages are different and that’s probably good
In many languages24, including Python, Java, Rust, sort() is stable by default and, if being honest, that’s a much better engineering decision, in my opinion. For example, Rust has .sort_unstable() which does not have stability guarantees but explicitly tells what it does. However, C++ has a different priority, or, you may say, direction, i.e. usages of something should not do more than requested (a.k.a “You don’t pay for what you don’t use“). From our benchmarks std::stable_sort was 10-15% slower than std::sort, and it allocated linear memory. For C++ code that was quite critical given performance benefits. I like to think sometimes that Rust assumes more restrictive defaults with possibilities to relax them whereas C++ assumes less restrictive defaults with possibilities to tighten them.

Logical Bugs
We found several places where users invoked undefined behavior or made inefficiencies. Let’s get them from less to more important.
Sorting of binary data
If you compare by a boolean variable, for example, partition data by existence of something, it’s very tempting to write std::sort call.
However, for compare functions that compare only by boolean variables, we have much faster linear algorithms, named std::partition and for stable version, std::stable_partition.
Even though modern algorithms do a good job in detection of cardinality, try to prefer std::partition at least for readability issues.
Sorting more than needed
We saw a pattern of sort+resize a lot.
You can work out from the code above that although each element must be inspected, sorting the whole of ‘vector’ (beyond the 
Unfortunately, there is no stable std::partial_sort analogue, so fix a comparator if the determinism is required.
C++ is hard
If you have a mismatched type in a comparator, C++ will not warn you even with -Weverything. In the picture below zero warnings have been produced when sorting a vector of floats with std::greater<int> comparator.

Not following strict weak ordering
When you call any of the ordering functions in C++ including std::sort, compare functions much comply with the strict weak ordering which formally means the following:
- Irreflexivity:
is false
- Asymmetry:
and
cannot be both true
- Transitivity:
imply
- Transitivity of incomparability:
and
imply
, where

All these conditions make sense and algorithms actually use all those for optimization purposes. First 3 conditions set strict partial order, the 4th one is introducing equivalence relations on incomparable elements.
As you might imagine, we faced the violation of all conditions. In order to demonstrate those, I will post screenshots below where I found them through Github codesearch (https://cs.github.com). I promise I haven’t tried much to find bugs. The biggest emphasis is that violations do happen. After them we will discuss how they can be exploited
Violation of irreflexivity and asymmetry
This is a slideshow, look through it.




All of them violate irreflexivity, comp(x, x) returns true. You may say this might not be used in practice, however, we learned a tough lesson that even testing does not always help.
30 vs 31 elements. Happy execution vs SIGSEGV
You may remember that up to 30 elements for trivial types (and 6 for non-trivial), LLVM/libcxx sort uses insertion sort and after that it bails out to quicksort. Well, if you submit a comparator where conditions for irreflexivity or asymmetry are not met, you will find that with 31 elements the program might get into segfault whereas with 30 elements it works just fine. Consider this example, we want to move all negative elements to the right and sort all positive, same as some examples above.

We saw users writing tests for small ranges, however, when the number of elements grows, std::sort can result in SIGSEGV, and this may slip during testing, and be an interesting attack vector to kill the program.
This is used in the implementation of libcxx to wait for some condition to be false knowing we will at some point compare two equal elements:
Violation of transitivity of incomparability
You can construct an example where the 4 condition is violated
The worst that can happen in that case with the current implementation that the elements would not be sorted (not segfaults, although this needs a proof but the article is already too big for that), check out:

And again, if you use fewer than 7 elements, insertion sort is used, and you will not construct a counter-example where std::is_sorted is not working. Even though, on paper this is undefined behavior, this is very hard to detect by sanitizers or tests, and in reality it passes simple cases.
Honestly, this snippet can be as simple as:
Why? As doubles/floats can be NaN which means x < NaN and NaN < x are both false and that means x is equivalent to NaN thus for every finite x we have x == NaN but clearly x == NaN and y == NaN does not imply x == y.
So, if you have NaNs in the vector, calling std::sort on paper invokes undefined behavior. This is a part of the problem which was described in
Wait, but finding strict weak ordering violations takes cubic time
In order to detect strict weak ordering violations, you need to check all triples of elements which takes 
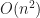
And we did what most engineers would do. We decided after randomization to check 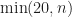
std::nth_element bug to randomization ratio is the highest. Here is why
Even though std::sort is used the most and found most failing test cases, we found that randomization for std::nth_element and std::partial_sort found more logical bugs per failing test case. I did a very simple codesearch query finding two close calls of std::nth_element and immediately found incorrect usages. Try to identify bugs on your own at first (you can find all of them in25):








All of them follow the same pattern of ignoring the results from the first nth_element call. The visualization for the bug can be seen in the picture:

And yes, this happens often enough, I didn’t even try to find many bugs, this was a 10 minutes skim through the github codesearch results. Fixes are trivial, access the nth element only after the call being made. Be careful.
How can you find bad sorting calls among hundreds of places in your codebase?
Users even in small repositories call std::sort in dozens/hundreds or even thousands different places, how can you find which sorting call introduces bad behavior? Well, sometimes it’s obvious, sometimes it’s definitely not and exploration is another question which greatly simplifies the debugging process.
We used inline variables26 (or sometimes compiler people call them weak symbols) in C++ which can be declared in headers and set from anywhere without linkage errors.
This helped to find all stacktraces of std::sort calls and do some statistical analysis on where they come from. This still required a person to look at but greatly simplified the debugging experience.
A very small danger note
If the function backtrace_dumper uses std::sort somehow, then you might get into an infinite recursion. This method didn’t work from the first run as at Google we use allocator TCMalloc and it uses std::sort.

The same happened with absl::Mutex. These were funny hours finding out why unrelated tests failed 🙂
Also note that backtrace_dumper is likely needed to be thread safe.
Automating process by a small margin
Sometimes what you can do is the following:
- Find all
std::sortcalls through this backtrace finder - Replace one by one with
std::stable_sort - If tests become green, point to the user that this call is likely a culprit
- Maybe suggest replacing it with
std::stable_sort- Accepting a patch is sometimes easier than delegating to the team/person to fix it on their own
- If none found, send a bug/look manually
This speeded up the process, and some teams accepted std::stable_sort understanding performance penalties, others realized that something was wrong and asked for a different fix.
Chapter 3. Which sorting are we replacing with?
In a way, that matters the least and does not require so much attention and effort from multiple people at the same time. If anybody decides to change the implementation, with the randomization above, it is easier to be prepared, switch and enjoy the savings (alongside with the benefits of mitigating serious bugs) right away. But our initial goal of this project was to provide better performance so we will talk a little about it.
I also want to admit that the debates around which sorting is the fastest are likely never going to stop and nonetheless it is important to move the needle towards greater algorithms. I am not going to claim the choice we proceed with is the best, it just significantly improves the status quo with several fascinating ideas.
A side note on distribution
We found that both cases are important to optimize, from sorting integers where comparisons are very cheap to extremely heavy where compare functions are even doing some codec decompression and thus are quite expensive. And as we said, it is quite important to figure out some patterns.
Branch (mis)predictions for cheap comparisons
In the current implementation, sorting executes a significant number of branch instructions while partitioning the input about the pivot. The branches are shown above where their results decide to continue looping or not. These branches are quite hard to predict especially in cases when pivot is chosen to be right in the middle (for example, in random arrays). The mispredicted branches cause the process pipeline to be flushed and generally are considered harmful for the execution. This was quite known and carefully analyzed28, 29. In a way, it is sometimes better to choose a skewed pivot to avoid this heavy loop.

In order to mitigate this, we use the technique described in BlockQuickSort28.
BlockQuickSort aims to avoid most branches by separating the data movement from the comparison operation. This is achieved by having two buffers of size B which store the comparison results (for example, you can choose B=64 and store just 64 bit integers), one for the left side and the other for the right side while traversing the chunks of size B. Unlike the implementation above, it does not introduce any branches and if you do it right, compiler generates good SIMD code with wide 16 or 32 byte pcmpgt/pand/por instructions for both SSE4.2 and AVX2 code.

Same for ARM

Once we fill all buffers, we should swap them around the pivot. Luckily, all we need to do is find the indices for the elements to swap next. Since the buffers reside in registers, we use ctz (count trailing zeros, in x86 bsf (Bit Scan Forward) or tzcnt (introduced in BMI)), blsr (Reset Lowest Set Bit, introduced in BMI) instructions to find the indices for the elements, thus avoiding any branch instructions.

Benchmarks showed about 50% savings on sorting random permutations of integers. You can look at them in https://reviews.llvm.org/D122780
Heavy comparisons
As we removed the mispredicted branches, now it is more reasonable to get other heuristics, for example, the pivot choice.
The intuition behind is that a good pivot decreases the number of comparisons but increases the number of branch mispredictions. If we fix the latter, we can try to do the former as well. The more elements for pivot we consider in random arrays, the fewer comparisons we are going to make in the end.
Other small optimizations include unguarded insertion sort for not leftmost ranges during the recursion (out of all ranges, there is only 1 leftmost per each level of recursion), they all give small but sustainable benefits.
These are all in line with the pdqsort3 implementation which was quite acclaimed as a choice of implementation in other languages as well. And we see around 20-30% improvements on random data without sacrificing much performance for almost sorted patterns.
Reinforcement learning for small sorts
Another submitted change got some innovations in assembly generation for small sorts including cmov (conditional move instructions). This is the change https://reviews.llvm.org/D118029. What happened?
You might remember sort4 and sort5 functions from the beginning of the post. They are branchy, however, there are other ways to sort elements: sorting networks. They are the networks which abstract devices built up of a fixed number of “wires”, carrying values, and comparator modules that connect pairs of wires, swapping the values on the wires if they are not in a desired order. Optimal sorting networks are networks that sort the array with the least amount of such compare-and-swap operations made. For 3 elements you need to compare-and-swap 3 times, 5 times for 4 elements and an optimal sorting network for 5 elements consists of 9 compare-and-swap operations.

Optimal networks for bigger values remain an open question but how to break the conjecture the optimal networks for 11 and 12 elements you can read an absolutely amazing blog post Proving 50-Year-Old Sorting Networks Optimal30 by Jannis Harder.
x86 and ARM assembly have instructions called cmov reg1, reg2 and csel reg1, reg2, flag which move or select registers upon the value of comparisons. You can use that extensively for compare-and-swap operations.

And in order to swap 
cmov with 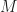
- For each comparison
cmpinstruction,movfor temporary register, 2cmovs for swapping. Togetherinstructions.
Together we have:
- Sort2 – 8 instructions (2 elements and 1 comparison)
- Sort3 – 18 instructions (3 elements and 3 comparisons)
- Sort4 – 28 instructions (4 elements and 5 comparisons)
- Sort5 – 46 instructions (5 elements and 9 comparisons)

However, as you can see, from the review above, sort3 is written in a little different way, with one conditional swap and magic swap.
And if we paste it to Godbolt, we will see that such code produces 1 instruction less. The 19th line from the left got to the 16th on the right and the 15th line on the left was erased completely.

I guess this is the reinforcement learning authors talk about in the patch. Generation helped to find an opportunity by finding that if in a triple (X, Y, Z) the last 2 elements (Y <= Z) are sorted, it can be better done in 7 instructions rather than 8.
- Move Z into tmp.
- Compare X and Z.
- Conditionally move X into Z.
- Conditionally move X into tmp
Move tmp into X.this was deleted- Compare tmp and Y.
- Conditionally move Y into X.
- Conditionally move tmp into Y.
For sorting 4 integers there is no optimal network with such a pair of comparisons but for sort 5 there can be up to 3 pairs. In the end, patch found how to save 1 instruction in each red circle below. They are exactly pairs of wires where 2 elements are already sorted .

In the end that helped to reduce the number of instructions per small cases from 18->17 when comparing 3 integers, 46->43 when comparing 5 integers. Then there comes a question: in order to minimize the number of instructions, we likely want to produce such networks with the most amount of such magic swaps, that’s an open and great question to think about.
Are they actually faster? Well, in 18->17 case it is not always like that because the removed mov is greatly pipelined. It is still less work for the processor frontend to decode the instruction but you are not likely to see anything in the benchmarks. For 46->43 the situation is the same.
LLVM review claimed to save around 2-3% for integer benchmarks but they all mostly come from the transition from branchy version to a branchless one. Instruction reduction does not help much but anyway is a good story how machine learning can help driving compiler optimizations in such primitives as sorting networks together with assembly generation. I highly recommend reading the patch for all C++ lovers, it has lots of lovely ideas and sophisticated discussions on how to make it right31.
Conclusion
How can you help?
There are many things that are not yet done. Here is by no means an exhaustive list of things you can help with:
- In debug modes introduce randomization described above.
- This can be done for the GNU library, Microsoft STL, other languages like Rust, D, etc.
- Introduce strict weak ordering debug checks in all functions that require it.
std::sort, std::partial_sort, std::nth_element, std::min_element, std::max_element, std::stable_sort, others, in all C++ standard libraries. In all other languages like Rust, Java, Python, D, etc. As we said, checking at most 20 elements per call seems to be ok. You can also introduce sampling if needed.
- In your C++ project try to introduce a debug mode which sets
_LIBCPP_DEBUGto some level27. - Consider randomization for the APIs that can be relied on at least in testing/debug mode. Seeding the hash function differently for not relying on the order of iteration of hashtables. If the function requires to be only associative, try to accumulate results in different order, etc.
- Fix worst case
std::nth_elementin all standard library implementations. - Optimize assembly generation for sorts (small, big, partitions) even further. As you can see, there is room for optimizations there as well!
Final thoughts
We started this process more than a year ago (of course, not full time), and the first primary goal was performance. However, it turned out to be a much more sophisticated issue. We found several hundred bugs (including pretty critical ones). In the end, we figured out a way to prevent bugs from happening in the future which will help us to adopt any correct implementation and, for example, see wins right away without being blocked by broken tests. We suggest if your codebase is huge, adopt the build flag from libcxx and prepare yourself for the migration. Most importantly, this effort produced a story on how to change even simplest things at scale, how to fight Hyrum’s Law, and I am glad to be a part of the effort to help open source learn from it.
Acknowledgements
Thanks to Nilay Vaish who pushed the changes for a new sort to LLVM, thanks to Louis Dionne, the maintainer of libcxx, who patiently accepted our changes. Thanks to Morwenn for outstanding work on sorting from which I learned a lot5. Thanks to Orson Peters and pdqsort which greatly improved the performance of modern in-memory sorting.
References
- The famous textbook from Cormen and others Introduction to Algorithms devotes over 50 pages to sorting algorithms.
- Ani Kristo, Kapil Vaidya, Ugur Çetintemel, Sanchit Misra, and Tim Kraska. 2020. The Case for a Learned Sorting Algorithm. SIGMOD ’20.
- Hackernews: “I think it’s fair to say that pdqsort (pattern-defeating quicksort) is overall the best”
- In-place Parallel Super Scalar Samplesort (IPS4o)
- https://github.com/Morwenn/cpp-sort — collection of most fun and efficient sorting algorithms written in C++
- libc++: A Standard Library for C++0x, Howard Hinnant, 2010 LLVM Developers’ Meeting
- One of the most popular sorting calls at Google ListFieldsMayFailOnStripped
- H. Mannila, “Measures of Presortedness and Optimal Sorting Algorithms,” in IEEE Transactions on Computers, vol. C-34, no. 4, pp. 318-325, April 1985, doi: 10.1109/TC.1985.5009382.
- https://en.wikipedia.org/wiki/C%2B%2B_Standard_Library
- Original std::sort implementation by Stepanov and Lee
- Antiquicksort: https://www.cs.dartmouth.edu/~doug/aqsort.c
- Quickselect
- nth_element worst case fallback in GNU libstdc++
- Fast Deterministic Selection by Andrei Alexandrescu
- Introsort
- Median of medians
- [libc++] Introsort based sorting function (2017, unsubmitted)
- libc++ has quadratic std::sort (reddit discussion)
- Add introsort to avoid O(n^2) behavior and a benchmark for adversarial quick sort input (submitted).
- [libcxx][RFC] Unspecified behavior randomization in libcxx
- ASLR (address space layout randomization)
- Sort added equal items ranges randomization (ClickHouse)
- bitsetsort peformance check (ClickHouse)
- Sort stability defaults in different programming languages
- All found open source issues (slides with repo names, commits and files)
- Inline variables in C++
- Debug mode in libcxx
- Stefan Edelkamp and Armin Weiß. 2019. BlockQuicksort: Avoiding Branch Mispredictions in Quicksort. ACM J. Exp. Algorithmics 24, Article 1.4 (2019), 22 pages. DOI:https://doi.org/10.1145/3274660.
- Kaligosi, K., & Sanders, P. (2006). How Branch Mispredictions Affect Quicksort. Algorithms – ESA 2006, 780–791. doi:10.1007/11841036_69
- Proving 50-Year-Old Sorting Networks Optimal
- Introduce branchless sorting functions for sort3, sort4 and sort5 (LLVM review)

I don’t know of many technical articles I’ve read in my life this thorough, comprehensive, and well-explained.
Thanks for taking the time to write this!
LikeLike
Typo: “… compare functions much comply …” should be “must comply”
LikeLike
Beautifully written article. Thank you for that.
LikeLike
Hi Danila Kutenin, great article. Moreover, great task to change std::sort.
I was working on sorting algorithms as a hobby since last year.
Would you have a look at my projects:
https://github.com/aldo-gutierrez/bitmasksorter
https://github.com/aldo-gutierrez/bitmasksortercpp
Maybe the only thing new that adds is the bitmask algorithm described there, to know how many bits are really been used(different) in the data to be sorted, in this way we can avoid some work to sort faster.
This bitmask takes less than 1% of the sorting time and can help in the choosing of the best algorithm. For example (not necessarily correct) if very few bits are used just use Count Sort, if many bits are used Radix Byte Sort otherwise RadixBitSort or QuickBitSort. I haven’t read all the articles on sorting, so maybe this has already been considered.
Thanks.
LikeLiked by 1 person
w.r.t. sorting floats, I wonder when c++ will get a IEEE 754 totalOrder predicate for doing the job. If/when they put one in, sorting floats could “safely” be done without type punning.
LikeLike
Hi, I enjoyed the article. Thanks!
> I guess this is the reinforcement learning authors talk about in the patch.
May I ask the title of the paper that uses reinforcement learning to write the patch?
LikeLike