TCMalloc team recently published a paper on OSDI’21 about Google’s allocator internals, specifically on how huge pages are used. You can read the full paper here.
TL;DR. Google saved 2.4% of the memory fleet and increased the QPS performance of the most critical applications by 7.7%, an impressive result worth noting. Code is open sourced, you can find it on GitHub.
My experience with huge pages has never been a success, several years ago at my previous company I tried enabling them and got zero results, surprisingly, I believe Google also tried them and got nothing out of just huge pages. However, if you see zero performance with better packing opportunities, it is worth trying to pack allocations together on such pages and releasing to the OS complete ones. This is a finally successful approach with significant gains.
A hugepage-aware allocator helps with managing memory contiguity at the user level. The goal is to maximally pack allocations onto nearly-full hugepages, and conversely, to minimize the space used on empty (or emptier) hugepages, so that they can be returned to the OS as complete hugepages. This efficiently uses memory and interacts well with the kernel’s transparent hugepage support.
Section 2
The paper is heavily based on some structure of TCMalloc, you can find a probably slightly outdated design in that link but let’s just revise a couple of points.
Objects are segregated by size. First, TCMalloc partitions memory into spans, aligned to TCMalloc’s page size (in picture it is 25 KiB).

Sufficiently large allocations are fulfilled with a span containing only the allocated object. Other spans contain multiple smaller objects of the same size (a sizeclass). The “small” object size boundary is 256 KiB. Within this “small” threshold, allocation requests are rounded up to one of 100 sizeclasses. TCMalloc stores objects in a series of caches.

The lowest one is per hyperthread cache which is tried first to satisfy the allocation (currently they are 256KiB) storing a list of free objects for each sizeclass (currently there are 86 or 172 of them which are defined here). When the local cache has no objects of the appropriate sizeclass to serve a request, then it goes to central and transfer caches which contain spans of those sizeclasses.
Some statistics
Most allocations are small: 55% of them are less than 8KB, 70% less than 1MB, 90% less than 10MB, other 10% grow linearly from 10MB to 10GB.

So most fight is going for small and middle sized allocations, up to several MB.
Temeraire
This technology (main contribution) replaces the pageheap with an ability to utilize 2MB hugepages. Paper tries to stick to several postulates
- Total memory demand varies unpredictably with time, but not every allocation is released. Paper argues that both types of allocations are important and there is no skew in any — long lived and short lived ones are both critical.
- Completely draining hugepages implies packing memory at hugepage granularity. Generating nearly empty hugepages implies densely packing the other hugepages.
- Draining hugepages gives us new release decision points. Returning pages should be chosen wisely, if we return too often, that is costly, if we return too rare, that would lead to higher memory consumption.
- Mistakes are costly, but work is not. Better decisions on placement and fragmentation are almost always better than additional work to make it right.
Then Temeraire introduces 4 different entities, HugeAllocator, HugeCache, HugeFiller and HugeRegion. And a couple of definitions: slack memory is a memory that remains unfulfilled in a huge page, backed memory is a memory which is allocated by the OS and in possession of a process and unbacked is returned to/unused in OS memory.
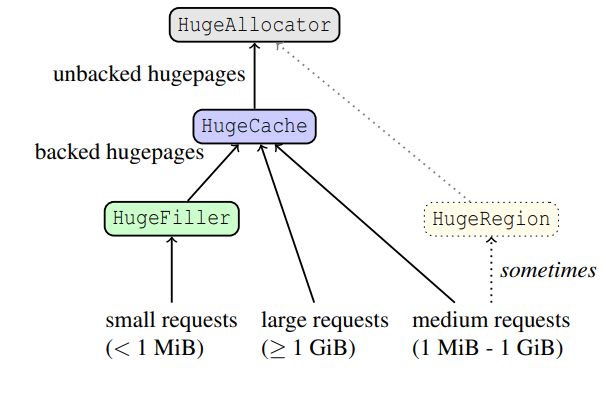
HugeAllocator deals with all OS stuff, responsible for all unbacked hugepages. HugeCache stores backed, fully-empty hugepages. HugeFiller is responsible for all partially filled single hugepages. HugeRegion allocator is a separate entity when medium requests are fulfilled by HugeCache with a high ratio of slack memory. HugeCache with all its slack memory donate it to HugeFiller to fill smaller allocations.
Several words about all allocators.
HugeAllocator
HugeAllocator tracks mapped virtual memory. All OS mappings are made here. It stores hugepage-aligned unbacked ranges. The implementation tracks unused ranges with a treap.
HugeCache
The HugeCache tracks backed ranges of memory at full hugepage granularity. This thing is tracking all big allocations and should be responsible for releasing the pages (making from backed to unbacked). However, if you just allocate-deallocate in a loop, you need to compute some statistics because lots of memory is going to be held unused. Authors suggest calculating the demand of how much memory is requested in a 2 second window and returning to the OS if the cache size is bigger than the peaks of the demand. One note: from code I see that they try to have several pages in the cache anyway (10, if being precise), I believe this is important as weird cases on small allocations can happen and releasing everything might be costly, having something backed is a good thing.
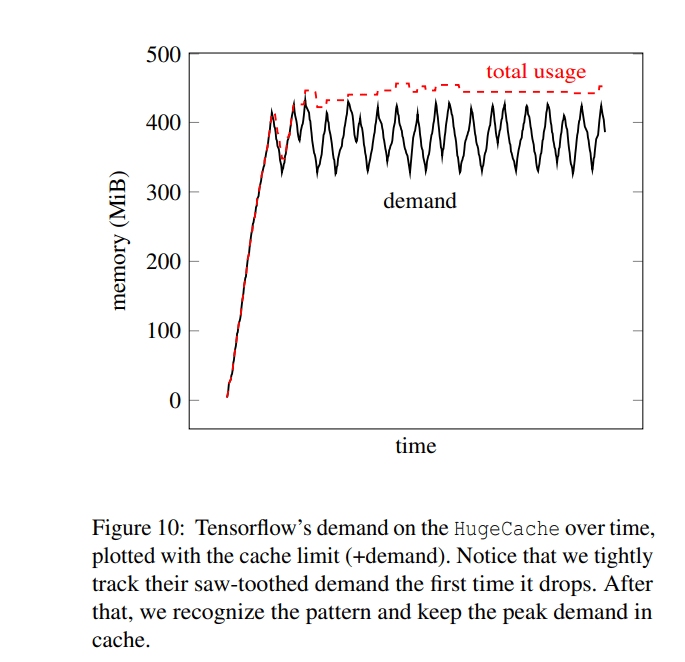
At the same time it helps to avoid pathological cases of allocating/deallocating things a lot and be on the same total usage, for example, see for tensorflow.
HugeFiller
Most interesting part, most allocations end up here. This component solves the binpacking problem: the goal is to segment hugepages into some that are kept maximally full, and others that are empty or nearly so. Another goal is to minimize fragmentation within each hugepage, to make new requests more likely to be served. If the system needs a new K-page span and no free ranges of ≥ K pages are available, we require a hugepage from the HugeCache. This creates slack of (2MiB−K ∗ pagesize), wasting space.
Both priorities are satisfied by preserving hugepages with the longest free range, as longer free ranges must have fewer in-use blocks. We organize our hugepages into ranked lists correspondingly, leveraging per-hugepage statistics.
Section 4.4
Inside each hugepage, a bitmap of used pages is tracked (TCMalloc pages); to fill a request from some hugepage a best-fit search is done from that bitmap. Together with this bitmap, some statistics is stored:
- The Longest free range (L). The number of contiguous pages (simple ones, not hugepages) not already allocated
- Total number of allocations (A)
Hugepages with the lowest sufficient L and highest A are chosen to place the allocation. The intuition behind that is to avoid allocations from hugepages with very few allocations. Then the radioactive decay-type allocation model is used with logarithmic scale (because 150 allocations on a hugepage is the same as 200 and smaller numbers matter the most).
HugeRegion
HugeRegion helps allocations between HugeFiller and HugeCache. If we have requests of 1.1MiB then we have a slack of 0.9MiB which leads to high fragmentation. A HugeRegion is a large fixed-size allocation (currently 1 GiB) tracked at small-page granularity with the same kind of bitmaps used by individual hugepages in the HugeFiller. Instead of losing 0.9MiB per page, now it is lost per region.
Results
Decreased TLB misses

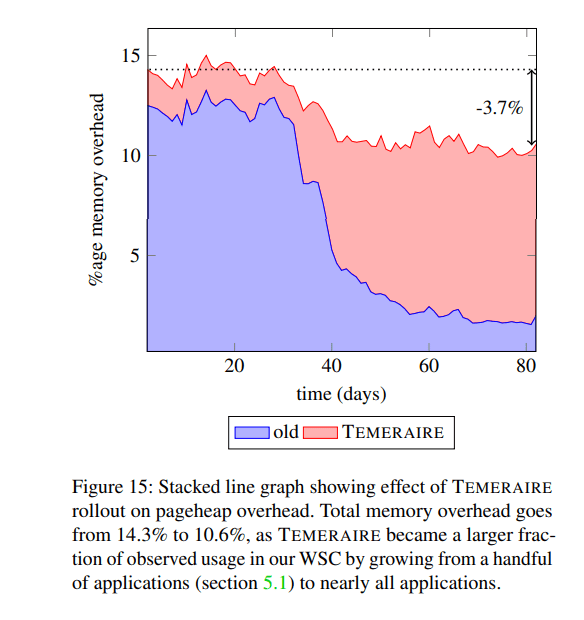
Overall, a point that stuck in my head is that “Gains were not driven by reduction in the cost of malloc.“, they came from speeding up user code. As an example, ads application showed 0.8% regression in TCMalloc itself but 3.5% improvement in QPS and 1.7% in latency. They also compare tens of other stuff but as you can guess, everything becomes better.
The best quote I found in this paper is probably not even a technical one but rather a methodological:
It is difficult to predict the best approach for a complex system a priori. Iteratively designing and improving a system is a commonly used technique. Military pilots coined the term “OODA (Observe, Orient, Decide, Act) loop” to measure a particular sense of reaction time: seeing incoming data, analyzing it, making choices, and acting on those choices (producing new data and continuing the loop). Shorter OODA loops are a tremendous tactical advantage to pilots and accelerate our productivity as well. Optimizing our own OODA loop–how quickly we could develop insight into a design choice, evaluate its effectiveness, and iterate towards better choices–was a crucial step in building TEMERAIRE.
Section 6
There is also the human side. Short OODA loops are candy. We really like candies and if some candy is taking too long, we go looking for another candy elsewhere.
Conclusion
Overall paper describes lots of ideas from allocators, how to build them, what should be considered as important and introduces finally a successful approach of supporting hugepages inside it with significant improvements which were mostly done by fast iterations rather than complex analysis and talent of ideas. Yet, there are still many other directions to try out like understanding immortal allocations, probably playing with the hardware, cold memory and further small and big optimizations, yet, this is a very well written and nicely engineered approach on how to deal with memory at Google’s scale.
