Hi everyone, hashcode is over. As now I can tell anything, I want just to tell how I was solving this problem, my methodologies, overall the structure of the data sets. I am not going to provide any internals and whatsoever, all data can be checked and much of it is my personal opinion though I had more time to reflect on it rather than contestants that only had 4 hours to solve it. So, I managed to get one of the highest scores (top 2, to be precise with the result 27,189,110) while testing the problem. Let’s talk about it. I provide all my solution data sets and pieces of code (though I don’t provide compilable repository because I am lazy, ok?). Please, get that this is an engineering research rather than a true contest full of combinatoric ideas. I suck at contests and don’t participate that often.
Here is the problem, very well written and explained. If converting it to a math problem, it is exactly this:
There are 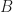
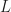



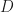

So, this is clearly an NP-hard problem. For example, the simplest reduction is a knapsack problem — assume that all daily throughputs are infinite and libraries do not overlap in their sets of books, then you need to maximize the sum of the libraries with a given budget
- In the optimal solution, books in all libraries must be sorted descending with respect to their scores. That’s easy to get and polynomial.
- The set of libraries matters because we are given the budget
- The choice of the books in the chosen libraries matters. For the books that are inside multiple libraries, it is sometimes crucial which library (or maybe not a single one) to choose to ship this book.
- The order of the libraries significantly matters. If you decide to push some library first with the install time
days to ship books.
Some good observations that always help for such kind of problems
- They are easily simulated — given the answer, you can calculate the exact score — that’s the first you should do in such research problems. It helps you to check thousands of different hypotheses.
- Freedoms are good to have some basic solutions. For example, I did not know how to optimize the books choices, I used the following technique: if there are multiple libraries for a book, choose one who has the biggest capacity for now. Overall, does not matter much which strategy, just try something reasonable and try different “reasonable” things to get fast and pretty sustainable results. This helped me to reduce the problem to just picking up a set and to start hacking.
But in order to start the actual hacking, some prerequisites.
Linear programming
This is a very sophisticated and interesting science about linear inequalities. Basically, you have a linear functional to maximize and a numerous of linear constraints to satisfy. One of the canonical forms looks like:
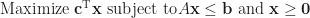


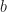
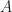

This is not the form you should stick to, for example the positivity property of the vector is not needed or can be additionally added (because any number can be represented as the difference between two positive ones). You can have any kind of inequalities (
Why is this important? The answer is that the all feasible solutions represent a convex polytope, matrix theory is also widely known and many optimization problems can be formulated in the form of some linear programs. The first and the second help to have many algorithms to solve as this area is widely known from many perspectives (maths and computer science), the last helps to solve many problems in a generalized way. You can assume that the “real world” solvers can solve linear programs with around 
Integer linear programming
The same as linear program but the solution vector 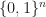
This area is less known and harder to optimize in the end. This happens because it is really hard to use methods from simple linear programs because the feasible solutions are extremely spare and proving that some solution is optimal is hard (and, of course, it is NP-complete which is one of the main reasons for a such complexity). Modern solvers can solve “real world” integer linear programs for around 
NP-completeness and hardness. P != NP
I hope most of my readers are familiar with these words. If not, google and read about this, right now, this is one of the most important things in the computer science overall.
A bit of philosophical reasoning. When people start programming, they express their thoughts inside the code to do something with the computer — to show some text, window, to compute some big expressions. Then, while educating, the problems become harder but still solvable. In many minds of the true beginners there sometimes can be a thought that computer can solve any practical problem (or at least, most of them). And then comes this monster, called NP-complete problems. This is a story about what the programmers cannot do.
There are several things in NP-completeness (further, NPC) right now. Discovering that some new problems are in NPC, either finding some approximations in some NPC problems or proving that some approximations of NPC problems are also NPC.
The first thing, reductions are very useful. They help to understand that if you can solve problem A, then you can solve problem B which is proven to be in NPC and then A is in NPC (I missed couple of details, does not matter). These reductions give a good understanding of what the hard problems are. A good intuition when the software developer gets that the challenging task comes to a very hard point and if the boss requires completing this task for 100%, the answer should be: “this problem is NP-complete, if I manage to solve it, I would be a millionaire and it does not matter whoever engineer you are going to hire”. Still, the “real world” is not black and white and we can something do about NPC problems — like finding approximations or trying to find some acceptable solution.
We need to admit that we need to solve these hard problems and that is what I do and don’t like about math at the same time — the math gives up and starts arguing that we need to stop solving this but the real world sometimes provide patterns inside the data which can be better approximated rather than the pure math says.
3SAT
3SAT is a classical NP-complete problem. Its main goal to satisfy the formulas with 
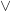

The problem is known to be hard and each NP-complete problem can be polynomial (from input size) reduced to it. Though, knowing the exact reduction is mostly useless (because the formula of cubed or even squared size can be unacceptable) does not mean that the world is not still going crazy and there are yearly SAT competitions. Minisat library is a good starting point for solving SAT formulas. Minisat can solve real world SATs with around of 
MAX-3SAT
This is the same problem but now we need to satisfy as many clauses as we can. This is more practical because mostly yes/no answer is not that important and some approximation can be a still acceptable and good solution.
Why is it important?
We face these problems quite often, for example, Sudoku for a field 

Complex 3SAT formulas
A very good question of producing really complex formulas still remains half open. In engineering part you can simply increase the number of variables and do some random stuff and a complex formula is going to happen at some point. Still a good question of producing rather small formulas making all solvers stuck and solve it forever. Only recently there was a paper around it with a pretty interesting results. It states that if the number of clauses (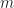


Engineering part in all this
There are many libraries and solvers that try to solve such complex problems. One of which I am used to and like the most is or-tools. It supports many languages and is a combination of many-many solvers. Has a pretty good documentation with many examples combining all the solvers such as GLOP, CLP, GLPK, SCIP and GUROBI. All these solvers are complex and require additional posts which will be interested only to some geeks. I would say that the advantage that you can try out many of them with one proxy that or-tools is providing. Many of the solvers can have a timeout and print the existing solution saying was it optimal or was not able to prove it. Also, most of the solvers accept a hint solution using which it can try something better around this solution — this is pretty useful, if you have some combinatoric idea, you can use the solvers to try out if they can find something better that you’ve come up with. Some of the solvers even support multithreaded mode but this is more an advanced feature and I haven’t seen much progress from it, solvers tend to roll down to some solution and don’t move out from it for a long time.
So, one standard thing within the optimization problems — research, check, put into the solvers, repeat. Let’s try to see how it works with the hashcode problem which is kind of optimization problem.
Into the details
Problem is hard to formulate in terms of integer programming mostly because we have libraries which order matters — linear equations don’t like ordering or otherwise we should create many new variables. I thought this is a bold strategy given the fact that the conditions are already pretty big for the integer programming. I decided to look precisely inside the datasets and let’s try to break each of them. Example is not an interesting one, so let’s skip it.
Read On

This is a pretty simple dataset, all books are of cost 100, libraries have its own books, no book in any two libraries, all libraries have the 1000 days to ship everything (1 book per each of the 1000 days), so it is ok get around 90% of the libraries. Actually, as no book is in two libraries, it is just optimal to pick all libraries in the ascending order of their installation time. This is the optimal and we get 5,822,900 points. Easy dataset to start.
Incunabula
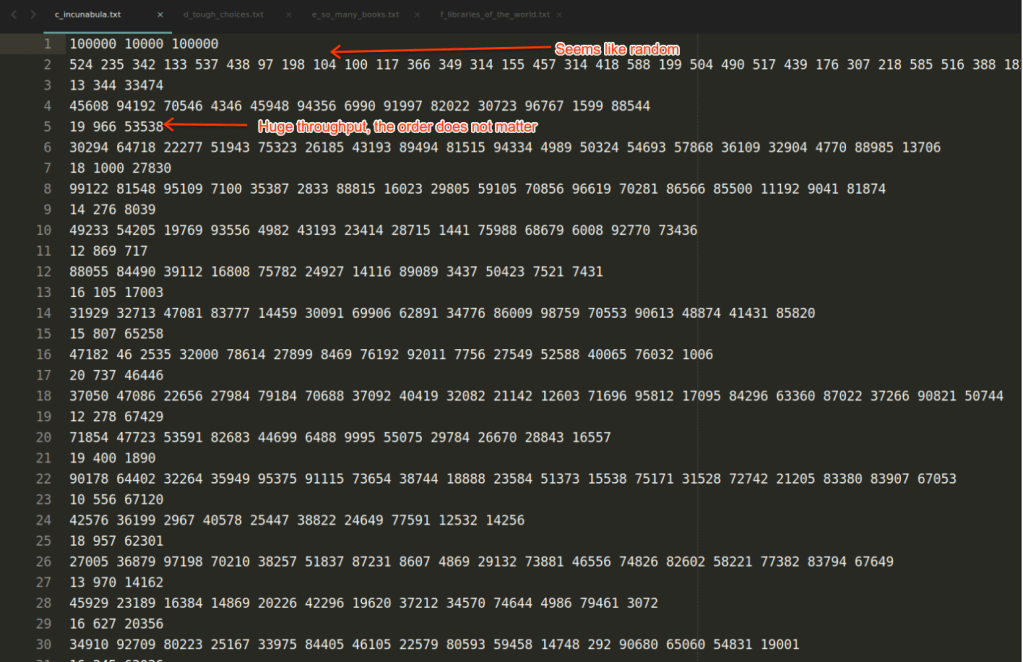
This is a harder dataset. All costs seem random, the books are in many libraries but I found that the throughputs are high. That means that the order in which we are shipping the libraries does not matter, matters the sum of the installation times. In this case it is a maximum budgeted coverage problem. Indeed
maximize 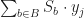
subject to 


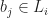


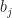

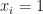

But if you will try to just put this the conditions inside the problem, the solver will not find anything cool in one hour. That’s why we need some sort of hinting. In that case I just came up with some greedy solution: pick the library that will give us the most value divided by the number of days it is installing, delete all books from other libraries, subtract the number of days and repeat the iteration. After some analysis, it can be proven this is a 
Tough choices
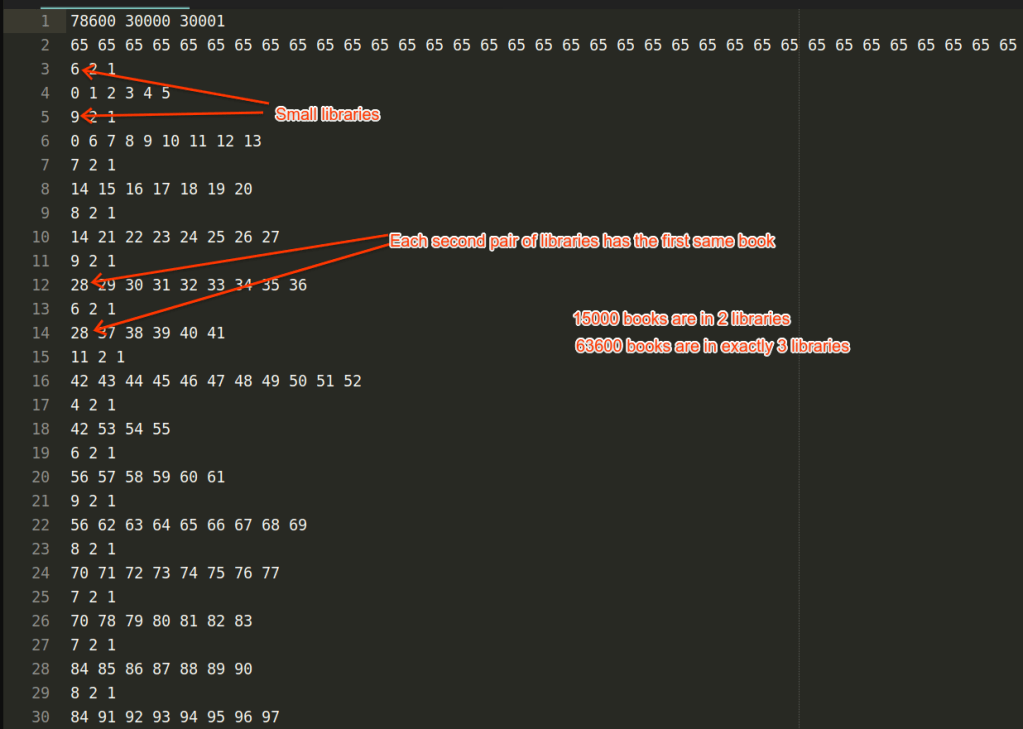
As long as I have somewhat greedy solution and written linear program, let’s dive into this dataset. This dataset has all books of equal cost. All libraries contain small libraries, that means we should not care much about the ordering — most books will be deployed.
Also, 15000 books are exactly in 2 libraries (and adjacent ones), 63600 books are in exactly 3 libraries. Also, after that I found out that 
The world is, of course, correct, I tried pushing this 3SAT inside Minisat and it did not manage to find any good solution for a long time and I gave up. Luckily, I could push it to the integer programming solvers and optimize the coverage of the books. Greedy solution from the previous solution gives 98% coverage (which results in ~5,006,820 points) which is already great. Some code prototype of the integer programming reduction can be found here. After 2-3 hours of waiting I got 99.75% of the coverage which resulted finally in 5,096,260 points. The solution you can find here. Solving it optimally is a really hard problem but having the 99.75% coverage is quite good.
So many books

This is the dataset I liked the most, overall I didn’t manage to prove something interesting here but at least I can tell how I was solving it. In this dataset the order of the libraries matters a lot and linear program is possibly only when the order of the libraries is fixed, then we can optimally choose which books should be chosen from which libraries. I decided to run a greedy solution and only somehow chose the books and got around ~5,100,000 points. Then I did not know how to correctly assign the books to the libraries and I just used the solver of the fixed order of the libraries and got ~5,200,000 points, so it turned out that optimal assignment gives lots of more points. Then I found out that the optimal assignment ignores cheap books aggressively and in greedy solution I started to choose which books I should account for the greedy solution choice, in the end I counted only the books with 99+ score and finally got 5,235,423 points which you can check with this solution and this linear program which worked for 10 seconds, so finding the optimal score for a greedy solution was pretty doable.
I do believe this dataset has much inside it and can be cracked better than by me. Still, I got +120k from the greedy solution which possibly gave me so many points.
Libraries of the world
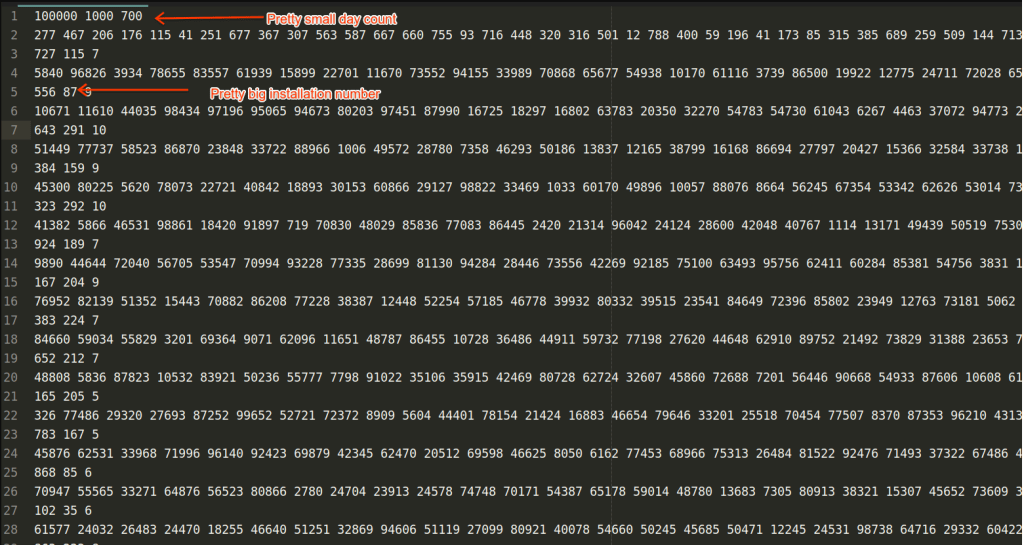
This dataset is a bit easier than the previous one because installation time is quite big and the day count is rather small. It turned out that likely optimal solutions are in a range from 15 to 18 libraries and this is a good number to try different permutations, some random removals and new additions. That I was doing — remove half of the libraries, add greedily to match the needs, run the solver (which solved optimally in 5ms), so I managed to try around 3-4 billion different permutations and variants. In the end simple greedy solution gave me ~5,312,895 points and I managed to get with this algorithm 5,343,950 points which you can check here. I think this value is not far from optimal, otherwise the solution is too far from the greedy one which I personally don’t believe given number of the variants I’ve tried.
Conclusion
I want to say that optimization problems arise in software engineering from time to time and it is essential to try some combinatoric solutions with the solvers — they can help find some interesting dependencies and optimize better your own solutions. Also, as there are many different solvers, it is easy to try them out given that or-tools already implemented a proxy where you can just change 1 parameter.
Also, hashcode is very fun to solve.
